Ballista, a distributed compute platform made with Rust and Apache Arrow
An interview with its creator, Andy Grove

An interview with its creator, Andy Grove
"I have become frustrated over the years with the proliferation of Big Data tools built in JVM languages. I understand the reasons for this — Java, and especially Kotlin and Scala, are productive languages to work in, the ecosystem is very mature, and skills are widespread. However, it really isn’t the best language for these platforms. The most obvious alternative has been C++ for a long time, but I thought it would be really interesting to see what was possible with Rust." — Andy Grove
As distributed computing platforms continue to become more relevant and new programming languages emerge with a modern approach and a focus on features that more traditional languages aren’t suited for, new and interesting technologies start appearing. In this interview, Andy Grove, software engineer and creator of Ballista, a fresh distributed computing platform built primarily on Rust and powered by Apache Arrow technologies, provides some insight on the motivations behind the project as well as the technical details and features that make Ballista different.
What is Ballista and what kind of problems does it solve?
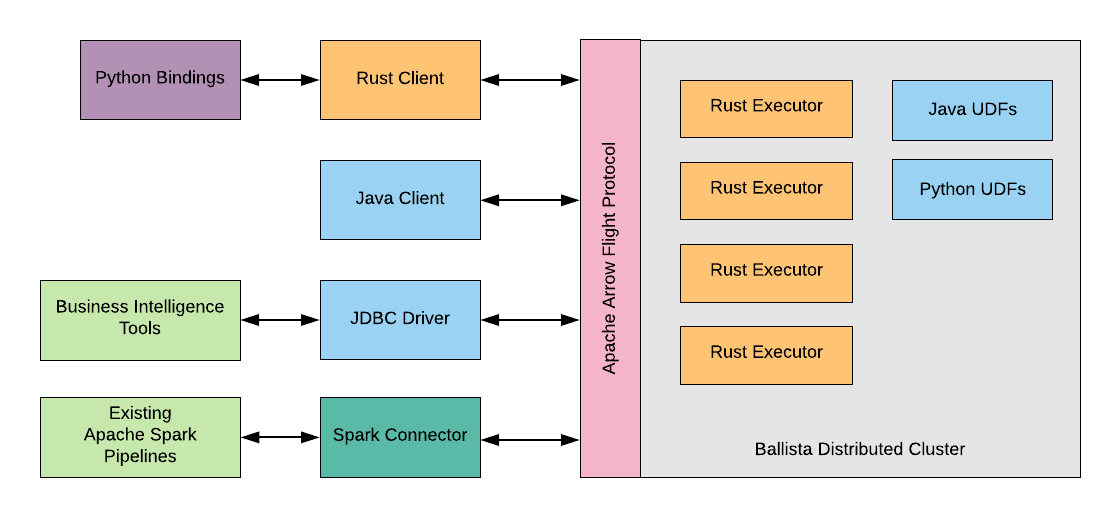
Ballista is a distributed compute platform with a current focus on executing ETL (extract, transform, and load) jobs based on queries which are defined using either a DataFrame API, SQL, or a combination of both.
Ballista is implemented in Rust and powered by Apache Arrow.
What are the main advantages of using Apache Arrow technologies?
In my opinion, there are quite a few advantages in using Apache Arrow for this project.
The Arrow memory format is optimized to support vectorized processing of columnar data and therefore enables significant performance improvements over row-based processing, especially when taking advantage of hardware that natively supports vectorized processing, such as SIMD and GPU.
Arrow also provides a “Flight” protocol, designed to enable Arrow data to be streamed efficiently (without serde overhead) between processes, and Ballista’s executors implement this protocol.
In addition to these benefits, Arrow is a standard that is becoming adopted more widely over time, so designing Ballista from the ground-up to be Arrow-native helps ensure compatibility with other projects in the ecosystem.
What are advantages of an implementation based on Apache Arrow over native data structures?
Arrow offers a mature type system and in-memory format for representing columnar data that has been tested and refined over many years, so I think this helps accelerate the development of the Ballista platform since there is no need to reinvent the wheel. It also ensures efficient compatibility with other projects that have also adopted Apache Arrow.
Can you tell us more about the Ballista query engine?
Sure. Ballista is based on the Volcano design but has less overhead as a result of being designed to process batches of columnar data. Its design is very much inspired by Apache Spark but with a focus on being language-agnostic so that it can efficiently support popular programming languages such Python, Java, and C++.
Ballista has a very similar usage to Apache Spark, what are the main advantages of Ballista over it?
The main advantages of Ballista (at least, once it is more mature) are:
Columnar Design
Although Apache Spark does have some support for columnar processing, it is still largely row-based. Because Ballista is natively columnar and is implemented in a systems level language, it can take advantage of vectorized processing with SIMD and GPU.
Language Agnostic
Apache Spark is implemented in Scala and tends to have a Scala-first approach, with other languages paying a penalty to interact with Spark due to overheads of serde. Ballista has been architected to use language-agnostic protocols and serialization formats to avoid this.
Memory Efficiency
Because Ballista is implemented in Rust, there are no GC pauses, and performance is very consistent and predictable. The combination of Rust and Arrow also results in much lower memory usage than Apache Spark — up to 5x lower memory usage in some cases. This means that more processing can fit on a single node, reducing the overhead of distributed compute.
How does it compare to Dask?
I actually do not have any experience with Dask yet, although it has been on my “to do” list for a while now. I have heard a lot of positive things about Dask and I am sure that I could learn a lot from this project.
Dask is obviously Python-centric, so I suspect that is going to be the main differentiator. Although the Ballista scheduler is being implemented in Rust, it is designed to work with executors implemented in any language due to the use of Arrow’s Flight protocol, and Google Protocol Buffers to represent query plans and scheduler tasks.
What are the reasons behind the choice of Rust as the main execution language?
The reason that I started this project (first with DataFusion at the start of 2018, and now with Ballista) is that I have become frustrated over the years with the proliferation of Big Data tools built in JVM languages. I understand the reasons for this — Java, and especially Kotlin and Scala, are productive languages to work in, the ecosystem is very mature, and skills are widespread. However, it really isn’t the best language for these platforms. The most obvious alternative has been C++ for a long time, but I thought it would be really interesting to see what was possible with Rust.
I see Rust as being a good compromise between Java and C++. It has the memory-safety of Java (but implemented in a very different way) and the performance and predictability of C++.
The cost of compute can be very high with Big Data platforms, so it makes sense to use a language that can make efficient use of the available memory and processing power on each node. In some cases, Ballista uses a fraction of the memory of an equivalent Apache Spark job, and this means that each node in a cluster can process a multiple of the amount of data that Spark can support, resulting in smaller clusters that are utilized more effectively.
Apache Spark has MLlib, a library for handling Machine Learning projects. What features does Ballista offer for these tasks?
So far, the focus of Ballista has very much been on ETL workloads. There have been some discussions about supporting ML workloads but this is an area that I do not have experience with so I am hoping that once Ballista is a little more mature in terms of ETL processing then we can start to look at other areas like ML and listen to what the current pain points are.
What will be the main areas of focus for future releases?
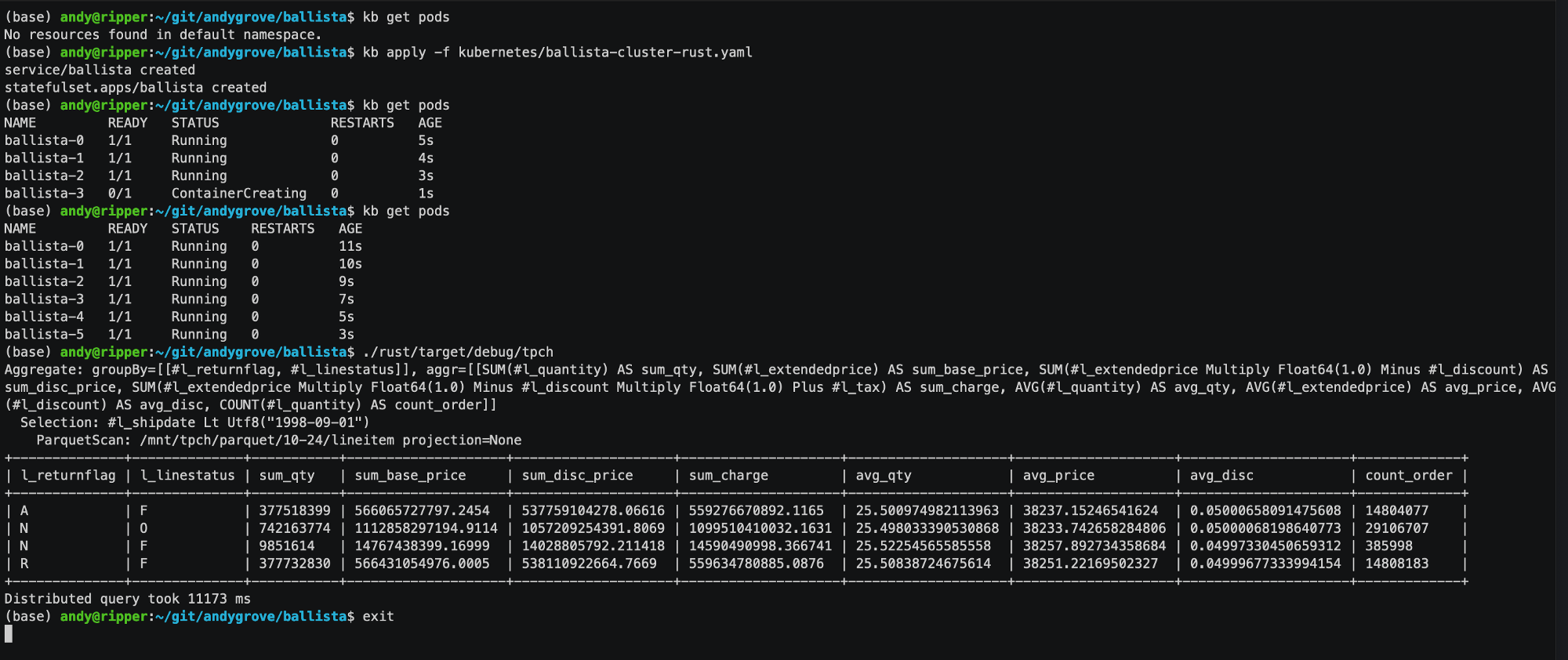
The main focus now is getting the platform to a level of maturity where users can run real-world ETL workloads, using the TPC-H benchmarks to measure progress.
Beyond performance, what are the next goals for the Ballista project?
Personally, I think that the most important goal for the Ballista project is to build a community around it. It started out as a personal side-project but I can only commit a relatively small number of hours each weekend to work on the project, and that time is better spent on writing requirements and building a community than trying to code everything myself.
To this end, I have started a weekly newsletter, named “This Week in Ballista”, to share news about progress and where help is needed. I am mostly spending my time on the project on tasks such as filing issues and responding to questions in Discord. I am also prototyping new features and then asking for help from the community to complete them.
Do you have any book recommendations on distributed computing?
Last year, I wrote “How Query Engines Work”, which is an introductory guide to query engines and it does cover distributed computing at a high level. I would be hesitant in recommending this book specifically to learn about distributed computing though, since it doesn’t have very much content on this subject yet, although I do plan on extending the content once Ballista is farther along.
