Ethrex L2: A Different Approach to Building Rollups
We present Ethrex L2, a rollup stack built with a different set of priorities: simplicity, minimalism, and modularity.

The Ethereum Layer 2 landscape has evolved dramatically. What started as experimental scaling solutions has matured into a diverse ecosystem of rollups, each making distinct architectural choices about security, decentralization, and performance. Optimistic rollups trade immediate finality for simplicity. ZK rollups invest in cryptographic complexity for faster settlement. Based rollups inherit Ethereum's decentralization directly from L1 validators.
Each approach reflects different priorities. Each carries its own trade-offs.
This post introduces ethrex L2, a rollup stack built with a different set of priorities: simplicity, minimalism, and modularity; with the goal of offsetting the costs that stem from complexity and compound over time.
What is Ethrex?
Ethrex is a Rust implementation of the Ethereum protocol with two modes of operation:
ethrex L1 functions as a standard Ethereum execution client, participating in the network alongside Geth, Nethermind, Reth, and others. It implements the Ethereum specification with a focus on correctness and minimal resource usage.
ethrex L2 operates as a ZK-rollup client, where block execution is proven using zero-knowledge proofs and verified on Ethereum L1. The L2 inherits Ethereum's security guarantees through cryptographic verification rather than trust assumptions.
What makes ethrex unusual is that it was conceived as both from day one instead of an L1 client with L2 bolted on, or an L2 stack that happens to share code with an L1 implementation. The dual nature was intentional, shaping architectural decisions throughout.
The codebase sits at approximately 62,000 lines of code including the EVM implementation, the L2 stack, ZK prover integrations, TEE attestation code, and an Ethereum SDK. Other execution clients typically exceed 200,000 lines in their main repositories, often with additional dependencies pushing them beyond 300,000.
The LambdaClass team that built Ethrex has worked across cryptography, distributed systems, programming language design, and high-frequency trading, and their background informs the engineering choices visible throughout the project.
The Philosophy: Simplicity as Engineering Choice
Many established blockchain clients accumulate complexity over time. This happens naturally: legacy features need support for existing users, ambitious roadmaps add layers of abstraction, and the pressure to ship can leave technical debt unaddressed. The result is often systems that are difficult to maintain, audit, and reason about.
Ethrex takes a different path. The philosophy is stated simply: "Keep things simple and minimal."
This isn't minimalism for its own sake; there are practical reasons to care about code size and complexity:
Security. Fewer lines of code means a smaller attack surface. Security auditors can review the codebase more thoroughly. Vulnerabilities are easier to spot when there's less code to hide in.
Maintainability. Simple code is easier to understand, modify, and debug. New contributors can become productive faster. The team can iterate without fighting against accumulated complexity.
Performance. When the codebase is small enough to fit in your head, finding and fixing bottlenecks becomes straightforward. There's no need to trace through layers of abstraction to understand where time is being spent.
Auditability. For teams deploying rollups in regulated environments or high-stakes applications, being able to verify what the code does matters. A 60k line codebase is auditable. A 300k line codebase with complex inheritance hierarchies is a different challenge entirely.
The ethrex team tracks code size daily, with strict limits that trigger review if exceeded. They actively refactor to remove dead code. The codebase contains only 12 traits (considered excessive; actively being reduced) and 4 macros (3 for tests, 1 for metrics).
This discipline extends to dependency management. Vertical integration is preferred over pulling in external libraries that might bring their own complexity. Only post-merge Ethereum forks are supported; legacy features are deliberately dropped to avoid maintaining code that no longer serves a purpose.
The result is a codebase where most developers can understand the entire system. There are no "haunted forests" or "here be dragons" areas that only one person understands.
L2 Architecture Overview
An ethrex L2 operates as a ZK-rollup, meaning all execution happens off-chain while Ethereum L1 serves as the verification and data availability layer. Here's how the pieces fit together.
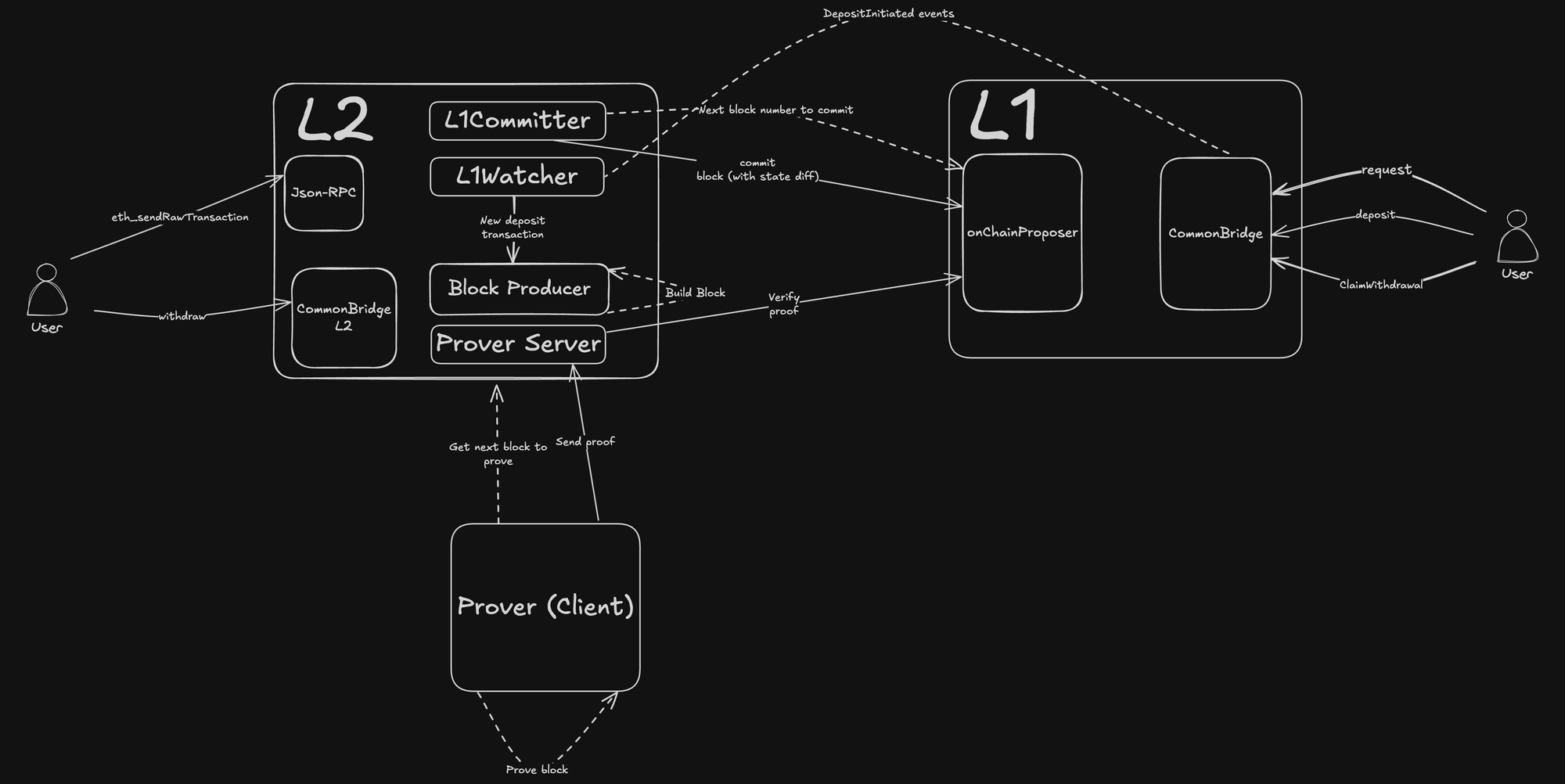
The Execution Flow
Users submit transactions to the L2 network. The sequencer collects these transactions and produces L2 blocks. Blocks are organized into batches for efficiency, since posting each block individually to L1 would be prohibitively expensive.
When a batch is ready, the sequencer commits it to L1. This commitment includes (among other data):
- The new L2 state root (a cryptographic summary of all account balances, contract storage, etc.)
- The latest block hash
- The transaction data (stored in EIP-4844 blobs
- A Merkle root of any pending withdrawals
At this point, the batch is "committed" but not yet "verified." The L2 state has been posted, but there's no proof that it was computed correctly.
The prover then generates a zero-knowledge proof of the batch execution. This proof attests that: given the previous state and the transactions in the batch, the new state root is correct according to the EVM rules.
Once the proof is generated, it's submitted to L1 for verification. The OnChainProposer contract checks the proof, and if valid, the batch becomes "verified." At this point, the L2 state inherits Ethereum's security: anyone can verify the proof on L1 and confirm that the state transition was correct.
Key Components
Block Producer. Creates L2 blocks from the mempool, assembling transactions into blocks according to gas limits and ordering rules.
L1 Watcher: monitors Ethereum L1 for deposit events from the bridge contract. When users deposit assets on L1, the watcher picks up these events and creates corresponding deposit transactions on L2.
L1 Committer: handles posting batch commitments to L1, managing gas estimation, nonce handling, and transaction retries.
Proof Coordinator: acts as a server managing communication with provers. It determines which batches need proving, provides the necessary input data, and receives completed proofs.
L1 Proof Sender: Submits verified proofs to L1, managing the interaction with the OnChainProposer contract.
Smart Contracts
CommonBridge (L1): Handles deposits and withdrawals between L1 and L2. Users call deposit() to move assets to L2, and claimWithdrawal() with a Merkle proof to withdraw back to L1.
OnChainProposer (L1): Manages batch lifecycle. Sequencers call commitBatch() to post new batches, and verifyBatch() to submit proofs. The contract tracks which batches have been committed and verified.
CommonBridgeL2 (L2): The L2 side of the bridge. Handles withdrawal initiation and processes deposit mints.
Data Availability
Transaction data is published using EIP-4844 blobs, Ethereum's dedicated L2 data storage mechanism. Blobs are approximately 128KB each and significantly cheaper than calldata.
Ethrex publishes full RLP-encoded blocks rather than state diffs. This provides complete transaction visibility, which matters for censorship resistance and allowing anyone to reconstruct L2 state independently.
Multi-Prover Architecture
One of ethrex's distinctive features is native support for multiple proving backends:
- SP1 (Succinct): A zkVM that compiles Rust programs to circuits. Supports both CPU and GPU proving.
- RISC Zero: Another RISC-V based zkVM with its own proof system. Also supports CPU and GPU.
- TEE Attestation (TDX): Uses Trusted Execution Environments to attest to correct execution. Faster than ZK proofs but with different trust assumptions.
Why does multi-prover support matter?
- Redundancy. If one proving system has a bug or vulnerability, you can fall back to another.
- Flexibility. Different applications have different needs. TEEs provide faster finality for applications that can accept their trust model. ZK proofs provide stronger guarantees for applications that need them.
- Future-proofing. The ZK space is evolving rapidly. New proving systems emerge, existing ones improve. Supporting multiple backends means you can adopt improvements without rewriting the stack.
This also reflects a philosophical choice: the low-level cryptography should be built by teams specializing in that work (Starkware's Stwo, Succinct's SP1, RISC Zero, etc.). Ethrex's job is to plug into their work, not to reinvent it.
This decoupling shows in the numbers: the entire l2/prover directory is approximately 1,300 lines of code. In other projects, ZK-related code often matches or exceeds the size of the non-ZK codebase.
Deployment Options
Ethrex offers three deployment modes, each with different trade-offs. The choice depends on your requirements for decentralization, cost, and operational complexity.
Vanilla L2 (Centralized Sequencer)
The simplest deployment model. A single operator controls the sequencer, producing blocks and committing batches to L1. How does it work?
- One entity runs the sequencer nodes and decides on transaction ordering
- That entity must post valid proofs to L1
- Users trust the operator not to censor transactions (though they can always force-exit via L1)
Trade-offs:
- Simple to operate and reason about
- Lower operational overhead
- Centralized sequencer can censor or reorder transactions
- Suitable for private deployments, enterprise applications, or getting started quickly
Validium
Similar to vanilla L2, but transaction data is NOT posted to L1. Only state commitments go on-chain.
- Sequencer operates as in vanilla mode
- State roots and proofs are posted to L1
- Transaction data is stored off-chain (requires a separate data availability solution)
- Users can still verify state transitions via ZK proofs
Trade-offs:
- Significantly lower L1 costs (no blob posting)
- Higher throughput potential
- Requires trust in the DA layer
- If DA layer fails, state can become unrecoverable
- Suitable for high-throughput applications where L1 DA costs are prohibitive
Based Rollup (In Development)
Decentralized sequencing where Ethereum L1 validators participate in block production.
- Sequencers register via the SequencerRegistry contract on L1
- Leadership is determined through a Dutch auction mechanism
- Round-robin election among registered sequencers (32 batches per sequencer)
- Anyone can verify proofs, not just the lead sequencer
- Nodes follow the lead sequencer via L1 syncing or P2P gossip
Trade-offs:
- Inherits Ethereum's decentralization
- No single point of failure for sequencing
- More complex operationally
- Currently under active development (we recently completed our first MVP milestone)
- Suitable for public chains that prioritize decentralization
The based rollup implementation is being developed in partnership with an upcoming permissionless L2 called Rogue. This provides a real-world deployment target for the based sequencing work.
Based Rollups: The Decentralization Path
Based sequencing deserves more explanation because it represents a fundamentally different approach to rollup architecture.
In most rollups today, a centralized sequencer determines transaction ordering. This creates a single point of failure and potential censorship. The sequencer operator has significant power: they see transactions before anyone else, can reorder for their benefit (MEV extraction), and can choose which transactions to include.
Based rollups flip this model. Instead of a dedicated sequencer, Ethereum L1 validators participate in L2 block production. The "based" name refers to using Ethereum's base layer for sequencing.
Ethrex's approach to based sequencing:
- Permissionless Registration. Any node can become a sequencer by registering on the SequencerRegistry contract and posting collateral (minimum 1 ETH).
- Auction-Based Leadership. Sequencing rights are allocated through a Dutch auction mechanism. Sequencers bid for the right to produce blocks during a given period.
- Round-Robin During Periods. Within an allocated period, registered sequencers take turns in a round-robin fashion (32 batches each).
- Anyone Can Verify. Proof verification is permissionless. The lead sequencer commits batches, but anyone can submit valid proofs.
- L1 Sync Fallback. Nodes that aren't leading can follow the current state by reading committed batches from L1.
The development of the based featureset is proceeding through the following milestones:
- Milestone 1 (MVP): Sequencer registration, round-robin election, L1 syncing. Complete.
- Milestone 2 (P2P): Block gossip, transaction broadcasting, sync optimization. In progress.
- Milestone 3 (Testnet): Public testnet deployment with monitoring.
- Milestone 4: Production hardening and optimization.
So what does the ethrex L2 stack provide? (and what to consider)
Being honest about capabilities and limitations is important when evaluating any technology. On one hand, the Ethrex L2 provides:
- Full EVM equivalence: Standard Ethereum tooling works. Existing contracts deploy without modification. The same development workflows apply.
- Multi-prover support: SP1, RISC Zero, and TEE attestation out of the box. Switch between them or use multiple simultaneously.
- L1/L2 bridge: Deposit and withdrawal functionality with proper Merkle proof verification.
- Aligned Layer integration: For teams using Aligned's proof verification infrastructure, integration is available.
- Straightforward deployment: A single binary handles deployment of L1 contracts and running L2 nodes.
On the other, as stated before, based rollup support is in-progress but functional for testing. Compared to other stacks, the ecosystem of tooling, documentation, and community resources is smaller.
Who is Building with Ethrex?
Aligned Layer chose ethrex as the foundation for their Rollup-as-a-Service platform. Their reasoning was that performance, minimalism, and based rollup-compatible architecture aligned with their needs. The integration enables one-click rollup deployment with Aligned's proof verification infrastructure.
Rogue is an upcoming permissionless based L2 being built on ethrex. It serves as both a production deployment and a development driver for based sequencing features.
Financial institutions have expressed interest in ethrex for private L2 deployments. The ability to audit a smaller codebase and the flexibility of deployment options fit enterprise requirements.
Finally, integration with Ethereum's infrastructure continues to advance. Ethrex was added to Ethereum's official Hive testing framework and the Kurtosis package for spinning up test networks.
The LambdaClass Approach
LambdaClass approaches crypto with specific beliefs. Open source is necessary, not optional, because decentralization requires transparency. Building in the open, helping onboard others, and creating movements bigger than individual projects are practical necessities for crypto to achieve its goals.
The work must put engineering first as an expression of a broader commitment to building technically excellent systems. We are very proud of what we have achieved in record time.
Ethrex represents a bet on simplicity in a space that trends toward complexity. We encourage teams that value an auditable codebase, deployment flexibility, and an architecture designed for based sequencing from the start to take a look.
The code is open. The documentation is at docs.ethrex.xyz. The team is accessible on Telegram and GitHub.
