Holiday Ping: how we implemented our first open source app with Erlang and Clojurescript
After almost ten years of working as a developer for different companies, two years ago I started my own company LambdaClass. I did so…

After almost ten years of working as a developer for different companies, two years ago I started my own company LambdaClass. I did so because I wanted to have more freedom in choosing the type of projects and team I work with.
That is why today it is a very special day for me. We take a break from regular interviews and celebrate the release of our first open source application: Holiday Ping. Facundo Olano is the main developer of the application. The application was written in two of the best programming languages we know (Clojure and Erlang) and our favorite database (PostgreSQL). This post was written by him and tells his journey and lessons learned with the backend side. A similar post on the frontend will be forthcoming. If you find any issue or want to help check github.
Discuss and vote at lobsters, reddit and hn.
Background
Earlier this year I joined LambdaClass, a Buenos Aires-based software consultant founded a while ago by some colleagues and schoolmates. LambdaClass has a special interest in distributed systems, and while it’s not exclusively an Erlang shop, most of its projects are implemented in BEAM languages.
Although I have a recent background in microservices and functional languages (mainly Clojure), I needed some time to ramp up and gain experience with the OTP platform and its underlying philosophy. I started working on some of the LambdaClass projects right away, but there are aspects of the learning process, specially those related with architecture and design, that are best experienced in greenfield projects. The company also has the goal of a strong open source presence, thus the decision to spend part of my time on public side projects.
We considered a couple of mid sized projects and implemented one of them (which arguably looked smaller in scope than ended up being). The purpose of this document is to share our experience, put some of our discussions into words so we wrap our understanding of them, and make conclusions that can help us in future projects.
The Project
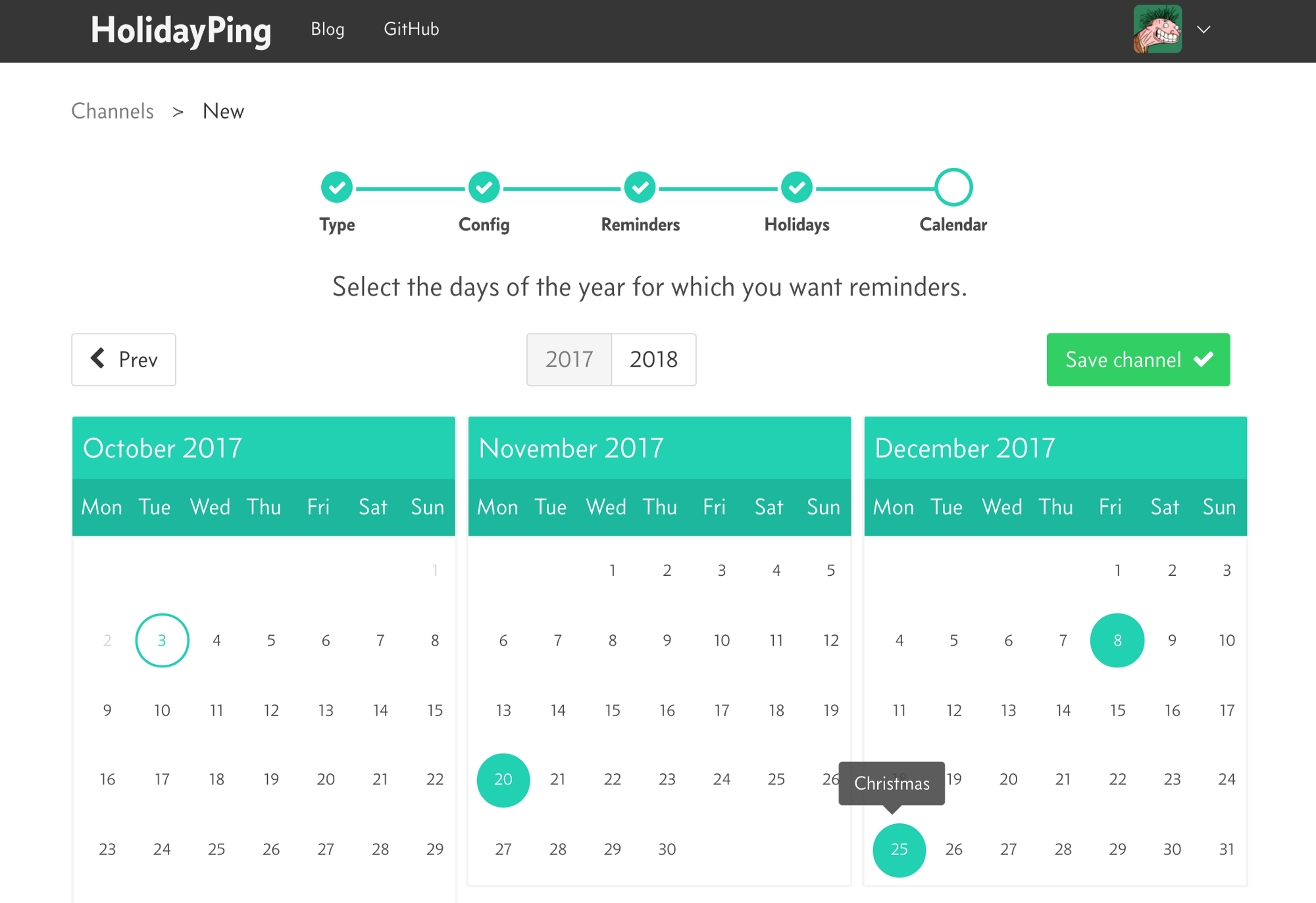
HolidayPing is a small web application that sends holiday reminders through different services like email and slack. It’s mainly aimed at consultants and freelancers used to work with clients abroad. It’s free of charge and open source.
Spin-off projects
As part of the HolidayPing effort, we have started to design and implement some open source tools that solve a couple of problems that we identify as recurring: throttle, to perform access control over resources such as API endpoints, and reconnections, to initiate and maintain connections to external services in an OTP idiomatic way.
The Backend
Language: Erlang vs. Elixir
The first decision was the programming language: Erlang or Elixir. We use both at LambdaClass, so I’d eventually have to learn them both, the question was which was more effective to learn first, considering both goals of being productive and properly understanding the Erlang platform in the long run.
Elixir would have probably been easier, considering my previous background and that it has a syntax closer to other modern languages. But learning it first carried the risk of just scratching the surface of OTP: using the language like it’s the new Ruby, and hiding what’s going on underneath. It does seem like it’s simpler to get a good understanding of the “OTP way” by starting with Erlang, especially since there’s literature that guides you through the process. Then, switching to Elixir would mostly consist of getting familiar with a new syntax and a few language features.
We understand that as Elixir is gaining popularity and more Elixir code is being written, a deeper understanding of Erlang and OTP will become a valuable asset for the company. In addition, many robust and useful libraries are written in Erlang and being able to dive in the code is important.
Learning Erlang
A quick note on my impressions of the language: I found it to be very expressive, mostly because of pattern matching; coming from Clojure, I didn’t have issues to grasp Erlang’s functional aspects; contrary to a lot of people, I don’t mind the syntax, I actually like it a lot with the exception of some notable quirks (one comes to mind: binary literals, while very powerful, are very inconvenient as a string replacement). As my coworkers kept telling me and I later confirmed: OTP is the big deal, and not the language itself.
Application and supervisor structure
At a high level, the application can be divided into the following components
- A RESTful API, mostly for CRUD operations.
- A Process that periodically checks whether reminders should be sent (e.g.: today is a holiday in Bob’s country, and Bob asked to send reminders through slack and email channels).
- Worker processes that send the reminders.
Rest API
The CRUD API didn’t require much thinking, at least from the OTP point of view. It’s implemented with Cowboy rest handlers, and I’ll just note that the library does a great job at forcing you to define a well behaved REST server without too much code.
Reminder checker
The processes involved in the reminders were more interesting, and obviously more important since the value of the application depends on them working properly (this is the “error kernel” of the app).
The process that checks whether holidays should be sent (remind_checker) is a gen_server that uses timer:send_interval to periodically query the database, asking what reminders should be sent. It then triggers worker creation with the necessary data to send the reminders.
How often the checker runs and what information is passed to workers are things that changed as the model and its implementation got more sophisticated, but the general idea was to always isolate the decision to send a reminder from the act of sending it, so a failure in a specific channel wouldn’t affect other channels, other users, or the checker process.
Reminder router
The reminders are sent by gen_server processes called reminder routers, which are children of a supervisor under a simple_one_for_one strategy. Different channel modules implement the specifics to send the message on each service (email, slack, webhook).
Why not gen_event?
While first studying OTP behaviors, my coworkers suggested I defer reading about gen_event, since it wasn’t used much in practice. When I started to work on HolidayPing, though, which is almost entirely about setting up and triggering events, it sounded like gen_event would be something to consider. And indeed a superficial overview confirmed that; quoting the Erlang in Anger book: a gen_event will act as an event hub for callbacks, or as a way to deal with notifications of some sort.
So I went back to my coworkers: how come we aren’t using gen_event for this? It turns out that this behavior doesn’t provide much of the benefits one would expect for such an event hub. In terms of what was discussed at the beginning of this section, gen_event does not provide isolation between events, so a slow or crashing event would affect the rest.
Why not worker pools?
At a certain point in the development, each router was sending the reminders for all the channels of a user on a given holiday. We wanted to further separate processing to have isolated channel requests (e.g. we don’t to bypass email sending if there was a crash requesting Slack).
The obvious option was to add a second simple_one_for_one supervisor with a new gen_server, but we briefly considered a worker pool instead. In other language ecosystems, where threads are expensive, a pool is an usual option. In Erlang, though, the story is different: processes are cheap and there’s no reason upfront to force a limit on the amount of processes being created (with some exceptions, such as maintaining a pool of connections to a database). And if you hit a point where there’s so much work to do that the amount of concurrent processes becomes too expensive, you most likely will need something fancier than a pool to overcome it (i.e. the pool manager will become a bottleneck or the queue will grow faster than workers can process it).
Admittedly, our situation is atypical in the sense that a potential overload wouldn’t come from requests constantly arriving, but a burst of reminders that need to be sent when the checker runs (currently every 15 minutes). We could easily alleviate this load by spreading the reminders through the time we have between one checker run and the next. Then again, it would be a useless optimization to do this upfront.
Avoiding throttling issues
Which brings me to an issue that we didn’t notice until I was writing these lines, and that’s still open. While we don’t have reasons to expect that our system won’t be able to handle sending all reminders at once, it’s likely that the third party services we hit will enforce throttling limits on us.
Let’s say that hopefully a thousand developers from Argentina find our project useful, and all of them set up a Slack channel, with the default reminder settings. If that’s the case, on Christmas morning at about 9:00am the reminder checker will attempt to send a thousand requests to Slack, more or less at the same time. Slack will likely reject those requests (and their retries next time the checker runs).
One way to reduce the chance of this happening, would be the same as mentioned in previous section: spread the reminder sending across the available time between one run and the next. Of course, with enough users the limit could be hit anyway and we’d have to resort to finer grained queuing or throttling mechanisms.
Database
The database pick was simple: PostgreSQL is the default database.
For me it had been years either hiding the database behind an ORM, or using schema-less stores like MongoDB. Although the lazy developer inside of me grumbled a bit at having to define the schemas upfront, I eventually came to remember how amazingly flexible and powerful PostgreSQL can be, to the point where I found myself pushing stuff (e.g. time arithmetics) to the database level because it was just easier to work with than the available Erlang libraries. We even want to explore domain integrity constraints to implement the long-postponed input validations on the backend.
Handle the configuration differences between channels
Our model had a spot that was hard to fit in the database schema: the user creates channels that can be of different types (Slack, email, webhook), each with different configuration parameters. The email channel takes a list of email addresses, webhook takes a single url, Slack takes an hook url, a list of channels and users, an emoji, etc.
We care about those differences only in each end of the application: when we validate the user input, and when we execute the type-specific logic to send a reminder; everywhere else, we want to treat the channels equally, regardless of the configuration. We tried several PostgreSQL features to save the channel configuration.
Inheritance
This use case seemed like a good fit for table inheritance: we wrote a base channel table with all the common fields (user, name, type) and separate tables inheriting from it adding the type-specific configuration. But we soon found out that inheritance features are very limited and don’t provide the features that would justify the choice: unique constraints aren’t enforced across children, you can’t get children’s data when querying the parent, etc.
Plain tables
Given that inheritance didn’t provide much operational value, using separate tables for configuration and managing them manually made more sense. This is the way to go in the long run, since we want to benefit from type validations and constraints, but compared with a schemaless storage, it would induce a lot of overhead in the early stages of development, considering the channel types and the model in general were far from being stable.
hstore
We started looking at unstructured PostgreSQL data types. hstore is a key/value type, but it doesn’t have arrays (e.g. more than one value per key). We needed this for channel options, so hstore didn’t do the trick.
jsonb
So we turned again to JSON. jsonb fields let us store arbitrary configuration inside the channel table, and treat it like an opaque value except on the spot where we actually use that configuration to send a reminder. Arguably this is the most convenient option only because we never got to the point of thoroughly validating channel input in the backend. When we get there, it will make sense to define properly structured tables first.
Rest API
Identifiers
We’ve spent some time discussing ways of identifying our resources across the project. This is a relevant discussion since it applies to most of our projects; we may as well settle with one design and be consistent from now on.
As we see it, the most flexible method is to use:
- A serial ID, just for PostgreSQL. Every table has it, you use it for foreign keys and joins. You don’t want to expose it in the API, since it’s implementation dependent, and something that may not be reusable should you want to switch databases (or add an extra one).
- A separate ID to uniquely identify the resource: a UUID that will never change and can be reused across databases.
- When it makes sense, a “model” ID for the resource (a user email, an unique name, etc.). You may use it as an identifier in the user facing API (i.e. in the REST uris or the UI routes), to make it user friendly. But you shouldn’t rely on it for internal storage and correlation: even if you start out with an “email won’t change” assumption, business rules like that do change and there’s no benefit in relying too heavily on them for your implementation.
The last one is something we didn’t get entirely right, and there’s still work to do. Our current implementation has model IDs (user email, channel name, holiday date), but no external UUIDs, so some use cases like changing a channel name are not supported.
Authentication and authorization
To manage authorization of the API, we went with Bearer tokens based on previous experience. What’s convenient about token authorization, as opposed to, say, requiring Basic Auth on every request, is that it allows us to decouple the authentication from the authorization: if we want to support a new authentication method (which we did when we added GitHub login), we just add a new auth endpoint that returns an access token; authorization on the rest of the API remains untouched.
Regarding the token format, I initially went with JWT without giving it much thought, because that’s what I’ve seen most commonly used to authorize web apps accessing a REST backend. My coworkers, who haven’t heard about it before, were suspicious, which I understand, because it totally sounds like:

And we’re not very fond of JSON. So I digged up a little bit more to make sure the decision made sense. There are several articles expressing concerns about using JWT, although most of them don’t apply to our use case. Assuming we want to stick to Bearer tokens, the alternative to JWT would be to just store a random string in the database, associated with the user, and check that value on every request. A quick comparison between the two options:
- JWT lets you identify the user without the need to hit the database on every request: the server decodes the token with the same secret it used to generate it, and checks the claims. To be fair, at least in our use case, there’s no evidence that going to the database on each request would be a problem.
- JWT is stateless, which seems to be more inline with REST principles: there’s no session, the client sends the token on each request which is enough to identify it.
- Database stored tokens require a bit of extra effort: we need to manage expiration ourselves, delete old tokens and make sure we pick a secure enough method to generate them. On the other hand, blacklisting compromised tokens is easier than with JWT, since we can just flag them in the database (although this is less of an issue using a short expiration).
In conclusion, JWT is easier (although it may not be simpler) than database stored tokens. Either option can work, and I don’t see a strong enough reason to drop JWT having that already working.
Nested resources
This is one of the things that we debated but didn’t get to a definite answer. We have these restful resources:
/api/channels/:name
/api/channels/:name/holidays
/api/channels/:name/reminders
And at some point the UI needs to display a summary view that lists channels including their holiday and reminder information.
What do we do? We obviously don’t want to force the UI to collect the data by making two extra requests per channel in the list. We don’t want to have an API tailor-made for this specific client, either. And don’t say GraphQL, because this is nowhere near big enough to call for that. View saw two acceptable solutions:
- Use a generic query parameter like `?children=true` to indicate that all the children resources should be included in the response. The problem is that this is an all-or-nothing approach: with big enough resources, you may want some of the children and not all. I’ve seen APIs suffer from that, coming up with weird DSLs to recursively pick nested children in the responses (now, that is the case where you’d look at GraphQL nowadays).
- Consider the detailed version of the channel (the one that includes its children information) as a separate resource altogether. At first this too felt a bit like forcing the backend to fit a client need (and, to be honest, looking at the URIs /api/channels and /api/channels_detail didn’t help); but after some thinking: better to let resources reproduce and keep the interface as dumb as possible (i.e. no magic query parameters).
We could have gone either way. We chose the separate resource because it was easier to implement.
Tests
I think you can’t write serious software without some sort of testing. At some point it’s inefficient to try to make progress without having tests to have your back. But I also think there are situations where being obligated to add tests is counter productive. Apart from the one commandment: thou shalt test thy shit, I don’t like any kind of religiousness about testing. Some types of software benefit a lot from unit tests (testing specific functions, isolated from the rest of the system), some not so much; coverage can be a good indicator, but forcing a specific coverage level sucks; some people work better with TDD, some people work better by adding tests after having some working code; some stuff calls for testing every possible scenario, some for generative testing. Etcetera.
In my experience over the last few years, working on small APIs that mostly deal with connecting to and integrating with external services, there’s little benefit in making pure unit tests. You have to spend a lot of time building mocks to test glue code, and still the most common scenarios can totally fail. If your software deals mostly with integrations, then you need integration tests to have some sort of confidence that your project works and that you don’t break it when you modify it. Because I change it a lot, all the time; that’s something I am religious about: if you aren’t breaking any APIs, you have the time and you know how to put your code in a better shape, then you do it every time you can.
Fortunately my coworkers share the same vision, so for HolidayPing we focused on integration tests that make sure the project works as a whole, with a real database and sending actual reminders. At first with lots of shortcuts to make sure the internal parts were working, but eventually, as development moved forward and the API stabilized, we were able to rewrite the tests so they mostly talk to the external API.
To be continued…
