How ethrex Heals State During Snap Sync
How does snap sync ensure lower sync times for Ethereum nodes joining the network? We go into Ethrex's implementation in depth.

What does an Ethereum node do?
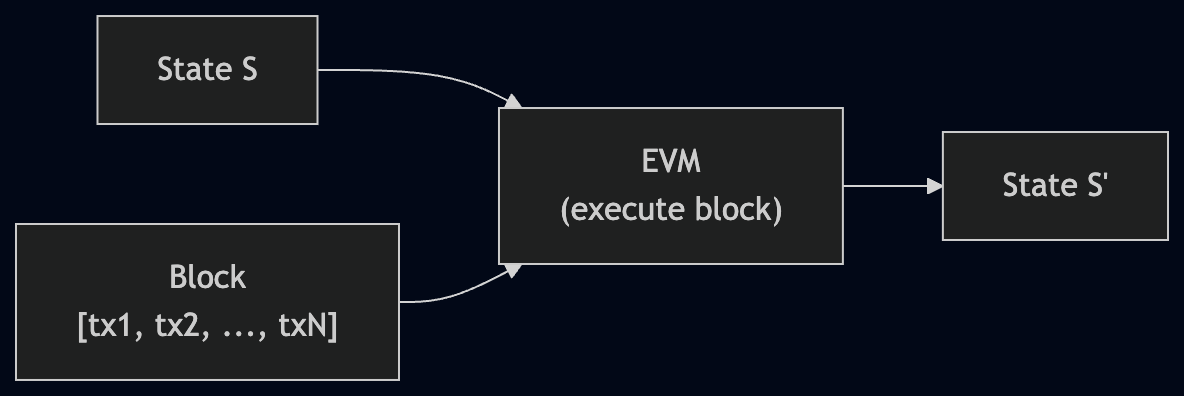
At its core, an Ethereum node executes blocks. A block is a batch of transactions, and each transaction is a state transition function: it takes the current state of the world (account balances, contract storage, bytecode) and produces a new state.
The EVM (Ethereum Virtual Machine) is the state machine that processes these transitions. Given state S and a block of transactions [tx1, tx2, ..., txN], the EVM produces state S':
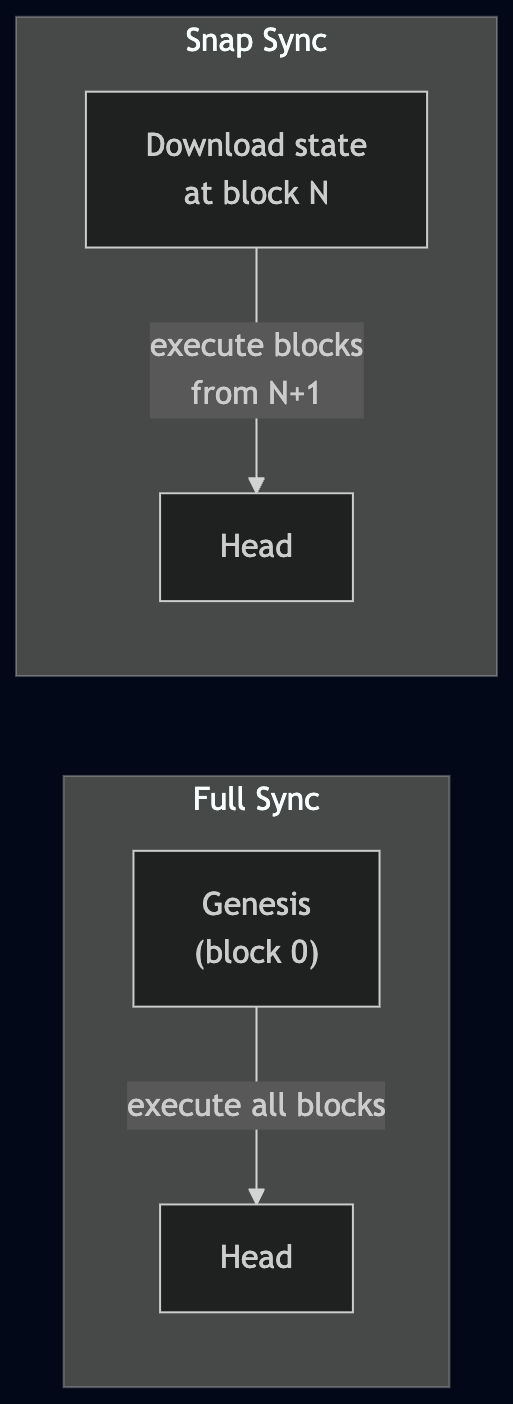
This means that to start functioning, a node needs an initial state. For nodes running full sync, that state is genesis — the hardcoded state at block 0. The node then re-executes every block ever produced to arrive at the current state.
But there's another option: download a state snapshot from somewhere in Ethereum's history and start executing blocks from that point forward. This is dramatically faster — you skip years of block execution and just need to catch up from your snapshot to the current head.
The challenge is: how do you download a state that has hundreds of millions of accounts?
What is snap sync
Snap sync is the modern approach to downloading Ethereum state. It evolved from an earlier method called fast sync, and understanding that evolution is key to understanding why healing exists.
The naive approach: fast sync
Ethereum stores its state in a Merkle Patricia Trie — a tree structure where the leaves hold account data and the root is a cryptographic hash that commits to the entire state. Each block header includes this state root, so anyone can verify that a state is correct.
Fast sync downloads this trie top-down. You ask a peer for the root node, then its children, then their children, until you reach every leaf:
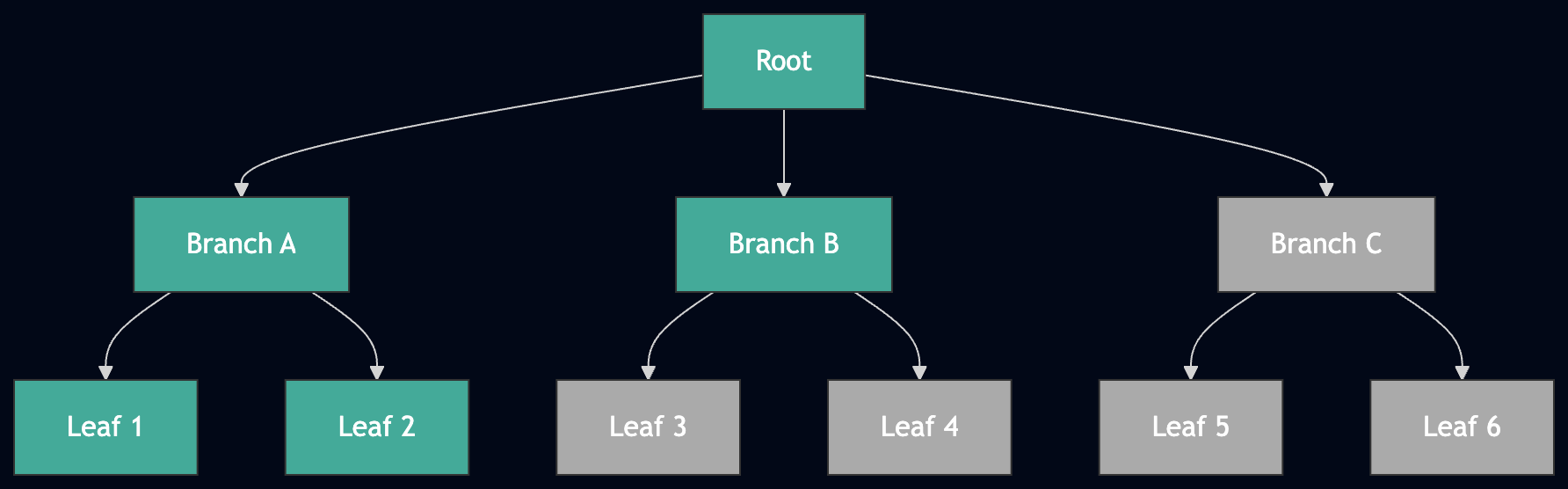
Fast sync in progress: green nodes are downloaded, gray nodes are still pending. The trie is traversed top-down, level by level.
The problem is twofold:
-
Peers stop serving old data. When you request a trie node, you specify a state root. If that root is more than 128 blocks old (~25 minutes), peers refuse to answer. Downloading hundreds of millions of nodes doesn't fit in 25 minutes, so you need to periodically switch to a newer state root (a new "pivot") and resume from there.
-
Scanning for missing nodes is expensive. After switching pivots, you need to walk the entire trie to find which nodes you're still missing. With millions of nodes already downloaded, this scanning dominates the sync time.
The insight behind snap sync
Snap sync flips the approach. Instead of downloading the trie top-down (root -> branches -> leaves), it downloads only the leaves — the account states and storage slots themselves — from peers. It then rebuilds the intermediate trie nodes locally from these sorted leaves. Computing trie nodes is far faster than downloading them over the network.
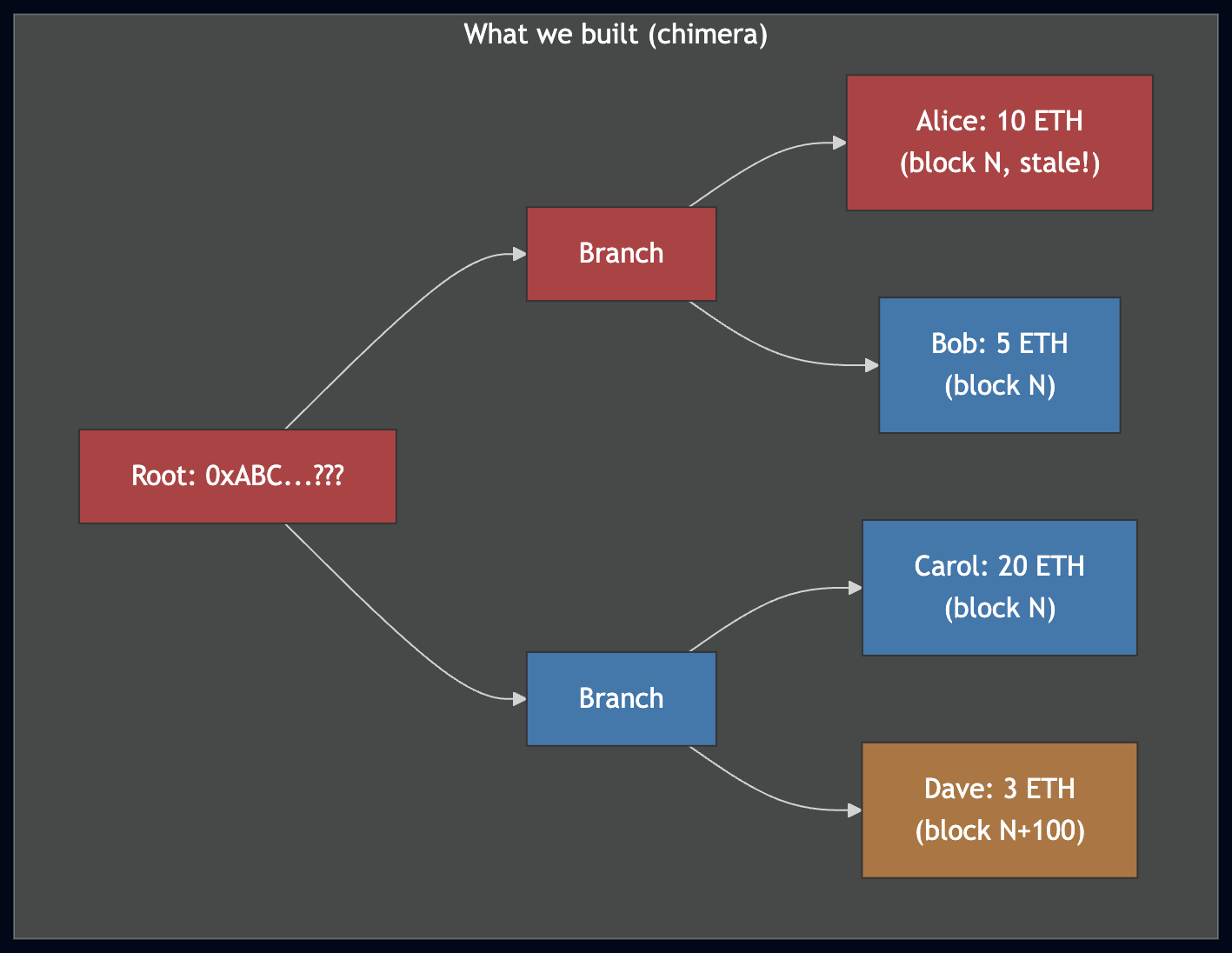
But there's a catch: downloading all the leaves also takes longer than 25 minutes. The pivot goes stale, we switch to a new one, and continue downloading. The resulting set of leaves is assembled from fragments of different blocks — a chimera that doesn't match any real on-chain state:

Leaves downloaded from two different pivots. Blue leaves came from block N, orange from block N+100. Some accounts may have changed between these blocks, so the combined set doesn't represent any real state.
This is where healing comes in.
The phases of snap sync
Snap sync proceeds in these steps:
-
Download block headers — Fetch all headers from the current head to the sync target. The range is split into chunks requested in parallel from peers.
-
Download account leaves — Using
GetAccountRange, download all account states. The key space is divided into chunks, buffered in memory (64 MB at a time), and flushed to disk as RocksDB SST files. -
Rebuild the state trie — Ingest the SST files into RocksDB, iterate the sorted accounts, and build the trie using an optimized sorted insertion algorithm. This produces a state root — almost certainly different from the pivot's actual root, because the leaves came from different blocks.
-
State healing + storage download — Heal the state trie so the root matches the current pivot. In parallel, download storage slot leaves for all accounts that have storage. If the pivot goes stale, update it and restart.
-
Build storage tries — Insert downloaded storage slots into per-account storage tries, again using sorted insertion.
-
Storage healing — Heal all storage tries whose roots don't match the current state.
-
Download bytecodes — Collect all code hashes seen during download and healing, then batch-fetch the contract bytecodes.
-
Switch to full sync — Store the pivot block, run
forkchoice_update, and switch to executing blocks going forward.
What is state healing
After downloading leaves from multiple pivots and rebuilding the trie locally, we have a trie whose root doesn't match any real block. Consider a simple example:
- We download 3 accounts at block N: Alice (10 ETH), Bob (5 ETH), Carol (20 ETH).
- The pivot goes stale; we switch to block N+100.
- We download 1 more account at block N+100: Dave (3 ETH).
- Between block N and N+100, Alice's balance changed from 10 ETH to 7 ETH.
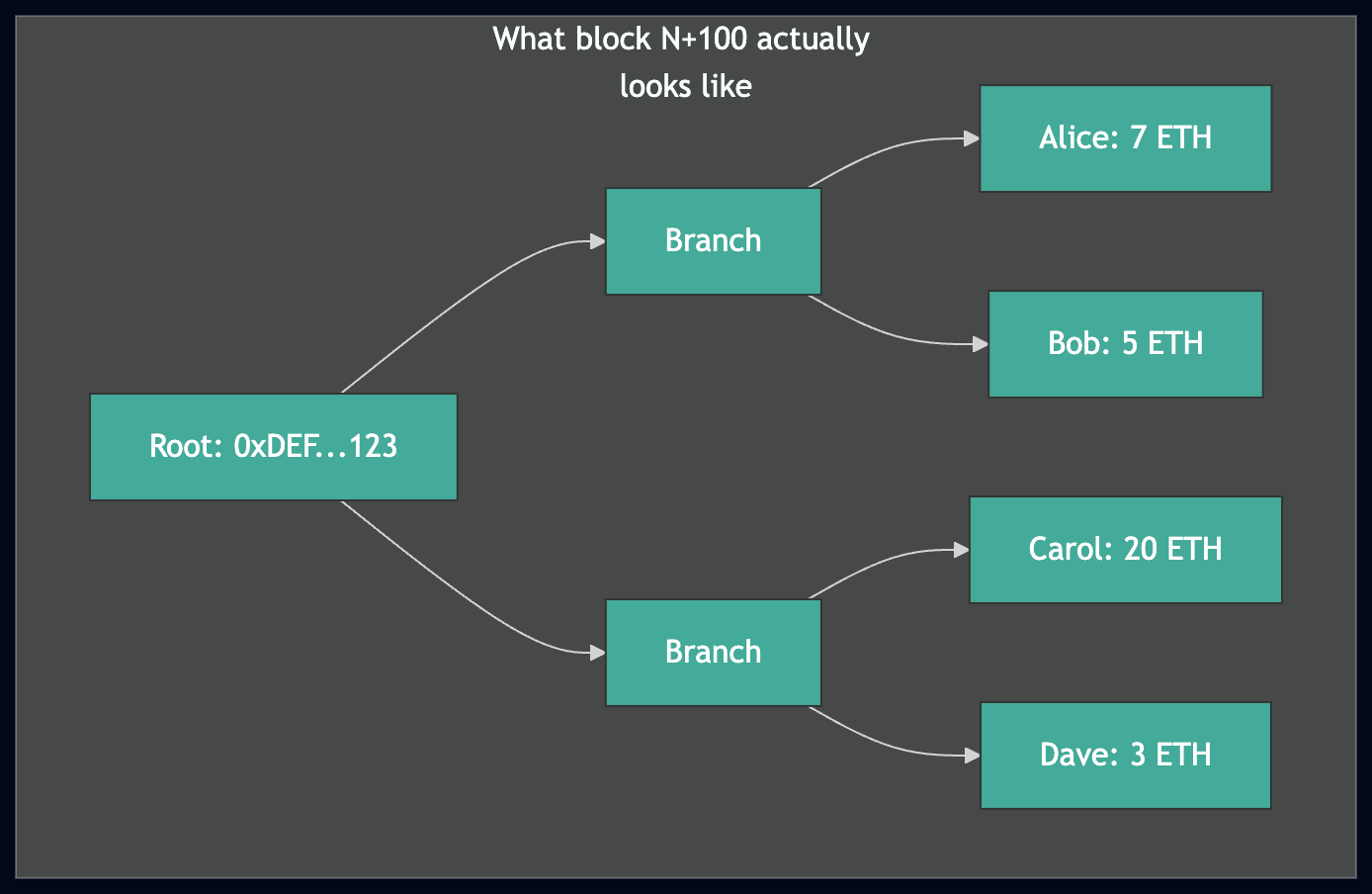
Above: the trie we built has a wrong root because Alice's balance is stale. Below: the real state at block N+100. Healing must fix the red nodes to make our trie match.
The trie we built from these 4 leaves is internally consistent (every branch correctly connects to its children) but its root is wrong — it doesn't match block N or block N+100.
State healing fixes this. It's essentially fast sync (top-down trie traversal) applied to our chimera trie. We start at the real state root for the current pivot and walk down: for each node, we check if it already exists in our trie. If it does, we can skip the entire subtree. If it doesn't, we download it from a peer and check its children.
The reason this is fast — the reason snap sync is 4-5x faster than pure fast sync — is that most of the trie is already correct. The leaves we downloaded and the trie we rebuilt give healing a massive head start. On the Hoodi testnet, pure fast sync takes ~45 minutes; snap sync with healing takes ~10 minutes.
Why healing is necessary
Without healing, we'd have a trie that we built locally but whose root doesn't match any block. We can't use it to validate new blocks, because Ethereum's consensus requires the state root in each block header to match the trie root you compute after executing that block's transactions. Healing bridges the gap between "most of the state is correct" and "the state is exactly correct."
How ethrex implements snap sync
The snap sync implementation lives in the ethrex-p2p crate, primarily in:
sync/snap_sync.rs— The main orchestratorsync/healing/state.rs— State trie healingsync/healing/storage.rs— Storage trie healingsync/healing/types.rs— Shared types (healing queue entries)
The pivot and staleness
The pivot block is the target whose state we're trying to download. Since peers stop serving data for roots older than 128 blocks, ethrex needs to detect staleness and update the pivot.
We use clock-based staleness detection rather than relying on peer responses. This is a deliberate choice: according to the spec, peers return empty responses for stale roots, but Byzantine peers may return empty responses at any time. So we simply check:
stale = current_unix_time() > block_timestamp + 128 * 12
When the pivot goes stale, we estimate a new block number:
new_number = old_number + (elapsed_seconds / 12) * 0.8
The 0.8 factor accounts for ~20% of slots being missed (no block produced).
The subtree invariant
The most important invariant in the entire healing algorithm is:
If a node is present in the database, then that node and all its children are present and correct.
This invariant is what makes healing efficient. When walking the trie top-down, if we encounter a node that's already in the DB, we can skip the entire subtree — we know everything below it is already there.
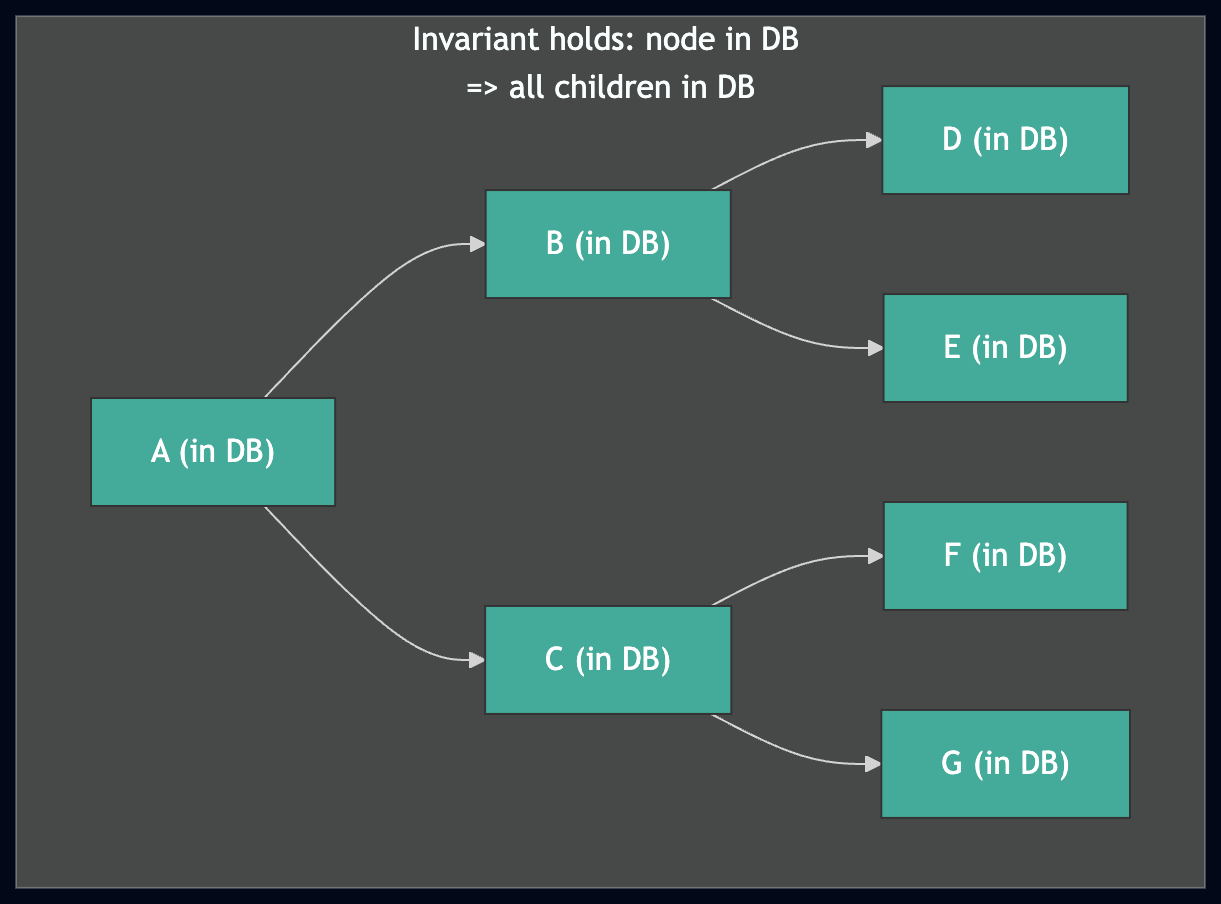
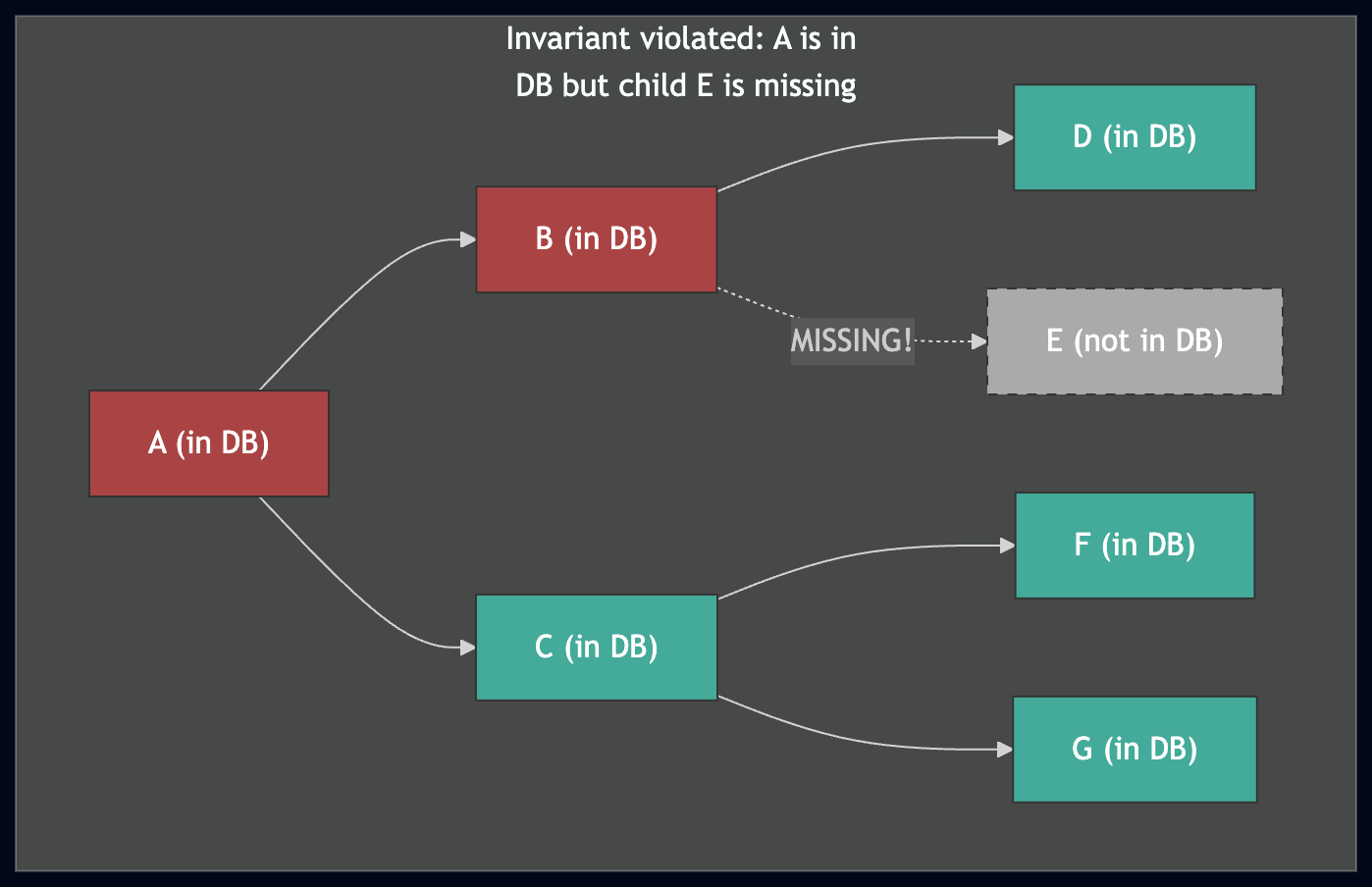
Top: the invariant holds — if the healer finds A in the DB, it can safely skip the entire subtree. Bottom: if the invariant is violated (E is missing), the healer would skip A's subtree and never discover the gap, resulting in a corrupted trie.
Maintaining this invariant during concurrent, interruptible downloads is the central engineering challenge of state healing.
How ethrex implements healing
The healing queue: a dependency-tracked write buffer
The core data structure is what we call the "healing queue" (inspired by geth's "membatch"). It solves a fundamental problem: we download nodes top-down (parent before children), but we need to persist them bottom-up (children before parent) to maintain the subtree invariant.
The healing queue is a HashMap that maps trie paths to entries:
pub struct HealingQueueEntry {
pub node: Node,
pub pending_children_count: usize,
pub parent_path: Nibbles,
}
pub type StateHealingQueue = HashMap<Nibbles, HealingQueueEntry>;
When we download a node, we check how many of its children are missing from the DB. If all children are present, we can write the node immediately. If some are missing, we store the node in the healing queue with a count of missing children, and add those children to the download queue.
When a child eventually gets downloaded and committed, we decrement its parent's counter. If the counter hits zero, the parent is committed too, which may cascade further up:
fn commit_node(
node: Node,
path: &Nibbles,
parent_path: &Nibbles,
healing_queue: &mut StateHealingQueue,
nodes_to_write: &mut Vec<(Nibbles, Node)>,
) -> Result<(), SyncError> {
nodes_to_write.push((path.clone(), node));
if parent_path == path {
return Ok(()); // We've committed the root
}
let mut entry = healing_queue.remove(parent_path)?;
entry.pending_children_count -= 1;
if entry.pending_children_count == 0 {
commit_node(entry.node, parent_path, &entry.parent_path,
healing_queue, nodes_to_write)?;
} else {
healing_queue.insert(parent_path.clone(), entry);
}
Ok(())
}
This creates a bottom-up commit wave: leaves commit first, then their parents, propagating up to the root.
Parent path deletion
When nodes are flushed to the database, we write them with a twist: all ancestor paths are written as empty bytes (tombstones):
for (path, node) in to_write {
for i in 0..path.len() {
encoded_to_write.insert(path.slice(0, i), vec![]);
}
encoded_to_write.insert(path, node.encode_to_vec());
}
This preserves the subtree invariant across healing cycles. If healing is interrupted by a stale pivot, the tombstones ensure that on the next cycle, the healing algorithm will re-download and re-verify the ancestor nodes against the new pivot's state root. Only the deepest committed nodes contain real data.
The state healing loop
The state healing algorithm (heal_state_trie in state.rs) is an async event loop:
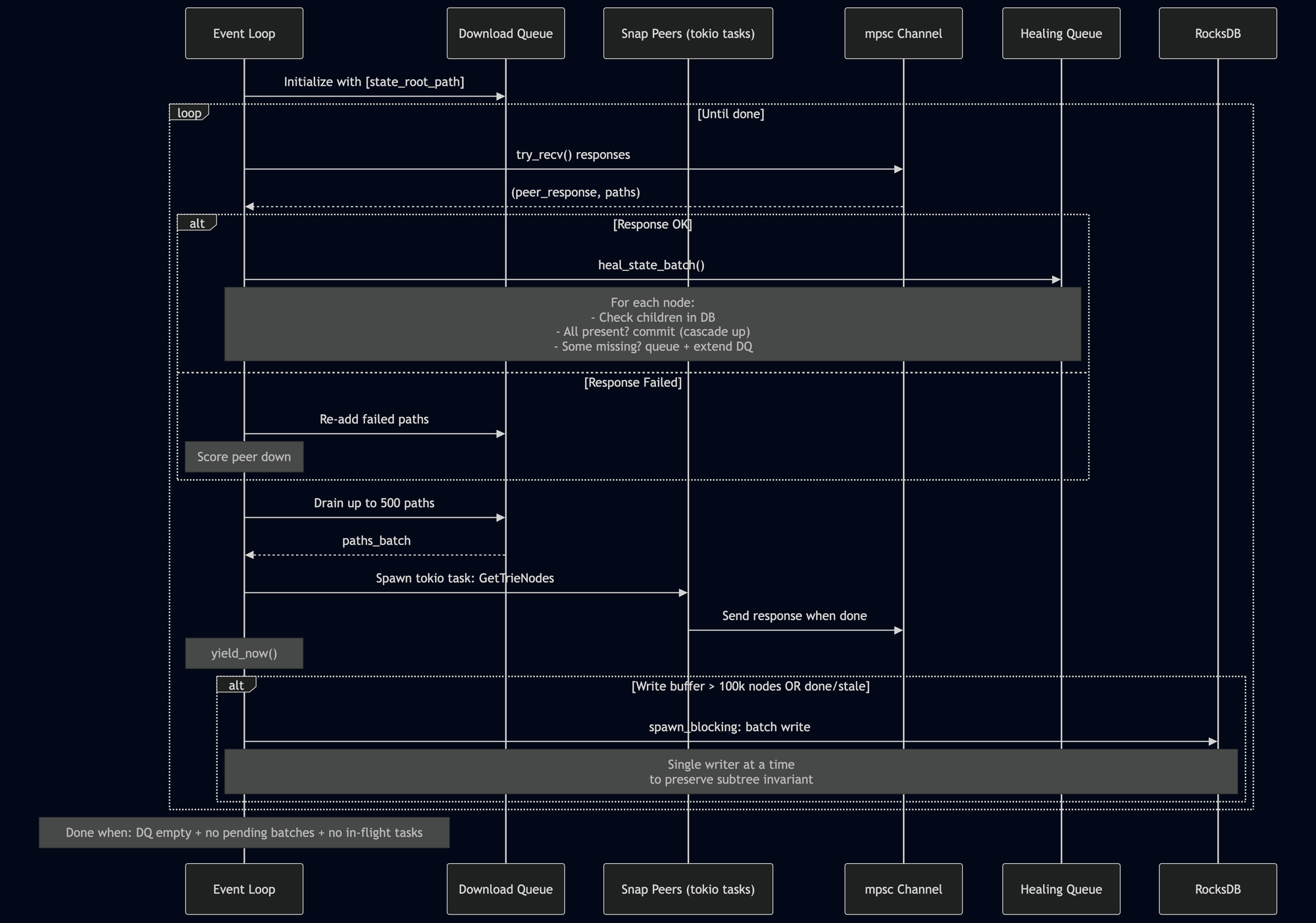
In detail:
-
Initialize with a single path: the state root itself.
-
Receive responses (non-blocking
try_recvfrom an mpsc channel). Successful responses are queued for processing; failed responses get their paths re-added to the download queue with the peer scored down. -
Send requests if not stale. Drain up to 500 paths from the queue, pick the best available snap peer, and spawn a tokio task to send a
GetTrieNodesrequest. Callyield_now()to let other tasks run. -
Process a batch via
heal_state_batch: for each downloaded node, check its children in the DB. If all present, commit it (potentially cascading). If some missing, add to healing queue and extend the download queue with the missing children. -
Flush to DB when the write buffer exceeds 100,000 nodes, or when done/stale. A single
spawn_blockingtask handles the write — only one at a time, to prevent out-of-order writes that could violate the subtree invariant. -
Terminate when the download queue is empty, no batches are pending processing, and no tasks are in flight.
During healing, every leaf node we encounter is also inspected: if it has a non-empty code hash, that hash is collected for later bytecode download. If the account has storage, it's marked for storage healing.
Storage healing
Storage healing follows the same conceptual algorithm as state healing — top-down traversal, healing queue, bottom-up commit — but with key differences driven by the fact that we're healing thousands of separate storage tries simultaneously.
Batching across accounts. The GetTrieNodes message allows requesting nodes from multiple accounts' storage tries in a single request. Storage healing groups requests by account path:
[[acc_path_1, storage_path_a, storage_path_b, ...],
[acc_path_2, storage_path_c, ...], ...]
This reduces round trips compared to one request per account.
Two-dimensional queue key. Since we're healing multiple tries at once, the healing queue is keyed by (account_path, storage_path) instead of just a path:
type StorageHealingQueueKey = (Nibbles, Nibbles);
pub type StorageHealingQueue = HashMap<StorageHealingQueueKey, StorageHealingQueueEntry>;
Parallel initialization. Before the healing loop starts, get_initial_downloads uses rayon's par_iter to read account states from the trie in parallel, determining which accounts have non-empty storage roots that need healing.
Capped concurrency. Storage healing caps in-flight requests at 77 (MAX_IN_FLIGHT_REQUESTS), whereas state healing is unbounded (one task per batch sent). The cap prevents overwhelming peers with too many simultaneous storage trie requests.
Struct-based state. Storage healing uses a StorageHealer struct to encapsulate all loop state (download queue, request tracking, metrics), making the code more organized than the variable-heavy state healing loop.
Concurrency model
Both healing algorithms share the same concurrency pattern:
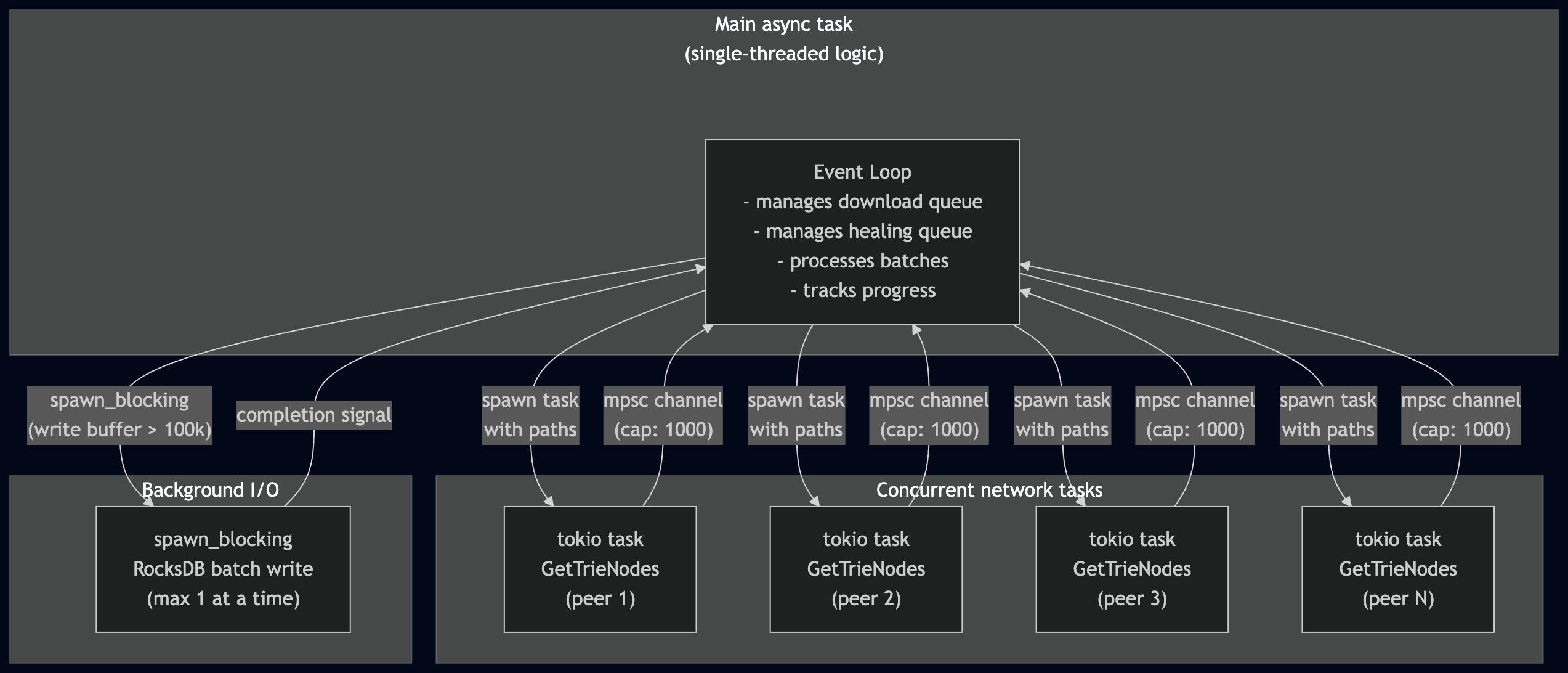
This design keeps the state management simple (no locks on the healing queue) while still achieving high throughput through concurrent network requests. The event loop is the only thing that reads or writes the healing queue and download queue — the tokio tasks only do network I/O and send results back through the channel.
Knowing when healing is done
State healing is complete when three conditions are simultaneously true:
- The download queue is empty (no more paths to fetch)
- No batches are pending processing
- No in-flight tasks are outstanding
Storage healing is complete when:
- The request map is empty (no in-flight requests)
- The download queue is empty
The outer snap sync loop runs both healings in sequence. If either returns false (interrupted by staleness), the loop updates the pivot and restarts. This means healing can span multiple sync cycles, progressively converging toward the correct state.
Progress tracking
ethrex tracks healing progress through several metrics:
global_state_trie_leafs_healed/global_storage_tries_leafs_healed— cumulative leaf counts- Peer count, in-flight tasks, longest path depth, download success rate, pending nodes in the healing queue
Progress is logged every 2 seconds. There's no explicit ETA — the nature of trie healing makes progress hard to predict, because a single branch node near the root can spawn 16 new download paths. The logged metrics give operators a feel for convergence: when the pending paths and healing queue are shrinking, healing is nearing completion.
Edge cases and caveats
The time-traveling problem. An account can change from state A to B and back to A across pivot changes. When it returns to state A, the node already exists in the DB — so healing skips it, even though the account's storage root may have been different at state B. This was a significant source of bugs during development. In our current path-based trie design, this is mitigated because healing overwrites previous state, but it remains something we test carefully. As a safety net, after 2 stale pivots during storage download, ethrex falls back to healing all remaining storage accounts rather than trying to download them.
Debug validation. In debug builds, after healing completes, the entire state trie and all storage tries are fully validated by recomputing roots from scratch. This is extremely slow but catches bugs with certainty — a validation failure means there is a bug in snap sync, period.
The SKIP_START_SNAP_SYNC flag. Setting this environment variable skips leaf download and goes straight to healing, effectively simulating pure fast sync. This is useful for testing the healing algorithm in isolation.
What's next
State healing is working and stable on mainnet. The areas we're actively improving include:
- Preserving the healing queue between cycles instead of clearing it on staleness — this would avoid re-downloading nodes we already have in memory.
- Checking the healing queue during child lookups — if a child is already in the queue, we can skip the download.
- Optimizing DB reads during storage healing initialization — the parallel trie lookups could be batched more efficiently.
The full snap sync code is open source at github.com/lambdaclass/ethrex in crates/networking/p2p/sync/. The internal documentation in docs/l1/fundamentals/snap_sync.md goes deeper into the protocol details and includes flowcharts for each phase.
