Interview with Jay Kreps about Apache Kafka
This time we interviewed Jay Kreps, one of the creators of Apache Kafka. Kafka is an open source messaging system with a few design choices…


This time we interviewed Jay Kreps, one of the creators of Apache Kafka. Kafka is an open source messaging system with a few design choices that make it particulary useful for high throughput and low latency scenarios.
“This experience lead me to focus on building Kafka to combine what we had seen in messaging systems with the log concept popular in databases and distributed system internals. We wanted something to act as a central pipeline first for all activity data, and eventually for many other uses, including data deployment out of Hadoop, monitoring data, etc.” — Jay Kreps
Kafka is built around the concept of a distributed database commit log. If you have no idea what that is, then I highly recommend that after you finish reading the interview you check the links I have pasted at the end. I learnt a lot by reading them.
In the following weeks I am going to publish an interview with Martin Kleppmann, one of the authors of Samza, about his book Data Intensive Applications and realtime stream processing systems vs batch processing systems.
What problem does Kafka solve?
Kafka is a distributed storage system for data streams. It allows you to publish streams of data and subscribe to them. It is built around the concept of a persistent log that is appended to — publishers of data append to this log and consumers subscribe to changes. Perhaps most importantly, it scales really well so it can function as a central hub for these data streams even in a company with a lot of data like LinkedIn or Netflix or Uber.
Why RabbitMQ, ActiveMQ and other similar open source projects where not useful to solve this problem?
There are a few things that are different about Kafka:
- It is built from the ground up as a modern distributed system. It handles replication, fault-tolerance, and partitioning. You think about Kafka as a cluster, not a collection of individual brokers. This impacts everything from how you manage it to how programs behave.
- Kafka does a good job of persistence. Data in Kafka is always persisted and can be re-read.
- Kafka is faster than traditional messaging system and hence more suitable to really large volume data streams such as would come from logging use cases, or massive streams of sensor data.
- Kafka was designed to support distributed stream processing as a layer on top of its core primitives. This is why Kafka is so commonly used with things like Spark Streaming or Storm.
In what type of structure do you persist messages and in which format?
A message or record in Kafka is just a key-value pair, where the key and value are some string of bytes.
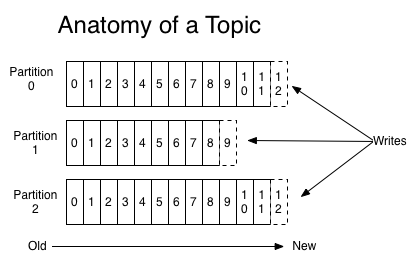
Kafka provides the abstraction of a “topic” which is split into one or more partitions (usually many) and spread over a cluster of nodes. A topic is a kind of feed of records. Applications publish records into a topic, and the record’s key determines the partition within that topic that the record goes to. Each partition is replicated on multiple machines for fault-tolerance.
The core abstraction Kafka provides (as well as the data structure it uses in its implementation) is a write ahead log. This log is just an ordered sequence of the records written to the cluster that is persisted to disk. Each record is assigned a sequential number called an offset. This offset acts as a position in the log.
An application consuming that partition can be thought of as having a position in the log designated by that offset, which means it has consumed all the records earlier and none of the records after. The application controls that position and can continue to read forward or go back in time to re-read.
How does Kafka manage to handle easily many dozens of thousand of messages per seconds if it persists them to disk instead of keeping them in memory?
Careful design! Our observation was that there was no fundamental reason that the log abstraction we wanted couldn’t be as fast as the underlying filesystem at linear writes, which means anything from hundreds of MB/sec on spinning disks to GBs/sec on SSDs. To make this happen Kafka does a good job of batching together lots of small writes into big linear appends to files. This batching happens both in the consumer, in the replication protocol, in the consumer, and in the operating system itself.
I do think the domain of infrastructure engineering is different in this way. Application developers are warned against the dangers of premature optimization, but for infrastructure I think you need to start thinking about performance in the design phase. The reason it is so different is that the fundamental constraints are well known ahead of time and usually system designs are not very flexible, so if you ignore performance initially it is generally very hard to get it back later by optimizing within your existing design.
What guarantees does Kafka provides? In which cases can messages be lost?
Kafka guarantees that writes are replicated across N instances in the same order (where N is a replication factor you choose) and that your write won’t be lost as long as at least one of these instance remains alive.
In combination with the way consumers control their own offset this translates to an “at-least-once” delivery.
In this talk you mentioned Kafka streams. Could you briefly explain what is it and why it will be useful?
Kafka Streams is a stream processing layer for Kafka we’ve been working on. It’s a little different from the existing stream processing frameworks that are out there — more focused on building streaming applications and less a kind of real-time version of MapReduce.
We’ll be doing a preview release in early March (we’re really excited).
Combined with the work we did on Kafka Connect, we think this makes Kafka a really compelling platform for streaming data.
What needs to be done before releasing Kafka 1.0?
We’ll get there. We thought we needed to at least get a stable version of Connect and Streams done as they are a pretty essential part of the platform.
Why did you choose Java to implement Kafka? Did you ever consider using another programming language?
We had a lot of experience with the JVM and knew it was possible to build reliable and fast infrastructure on top of it — and it was more convenient to work with than C or C++.
I work as an Erlang developer and I was thrilled by your comments about concurrency and languages in “Concurrency is not a language thing anymore”:
“In the near-real-time processing domain stream processing frameworks do a good job of providing asynchronous processing without directly thinking about concurrency at all. Again you interact with concurrency and parallelism only at the framework level, the code you write appears completely single-threaded.
The offline world seems to be moving in the direction of a handful of YARN frameworks for different specialized purposes. What almost all of these share is that they don’t require users to directly manage concurrency.
This leads me to think that putting more time into language support for single-server concurrency (software transactional memory and all that) is of limited utility. It will only help the implementors of these frameworks, not the end user.”
Apart from Erlang, some languages like Go and Clojure added a good concurrency model and semantics from the start. Don’t you think there is any area where having good concurrency baked into the language is useful for the normal developer and not only for the implementor of frameworks?
The critique I was trying to make is sort of analogous to the end-to-end principle for network protocols, basically you end up needing to solve the concurrency problem at a higher level anyway which makes the lower-level primitive the languages provide redundant. What I see is each language is trying to provide built-in primitives for multi-core programming. Other than Erlang I think most of these ignore the problem of distributed computing. But what has changed is that modern programming is always done in some framework that introduces a concurrency model at a higher level. Examples of these frameworks would be the whole Apple and Android stacks, numerous microservice frameworks, and things like Spark or Kafka Streams. These higher level frameworks are able to do a better job because they can make assumptions about the environment that just aren’t possible at the language level. So, for example, many of them are able to introduce a model that simultaneously solves for spreading computation over CPU cores on one machine as well as over multiple machines.
Why does Kafka depends on Zookeeper? What job does Zookeeper do for Kafka?
This article gives an overview of its role in Kafka’s replication design.
Do you have any recommendation for those of us who want to start learning about distributed systems? Was there any books, papers or codebase that really helped you implement and design Kafka?
I think a great place to start is Martin Kleppman’s book Designing Data Intensive Applications. I have only read parts of it, but from what I’ve seen it is the best accessible introduction to distributed systems out there. Unfortunately only 9 of 12 chapters are available so we should all bug him to finish it!
A good textbook you can buy today is Introduction to Reliable and Secure Distributed Programming. This book isn’t great for learning but it is an order of magnitude better than other text books which are utterly terrible. Unfortunately distributed systems research had several decades in which it wasn’t really very practical and hence it developed a culture that seems to pride itself on it’s lack of connection to mainstream practice. For example, that book, manages to spend on the order of a hundred pages introducing different possible communication primitives and talking about their properties without bothering to connect any of these to the actual mainstream network protocols like UDP and TCP which seems pretty silly to me.
The best thing is that these days there are hundreds of open source distributed systems available and you can learn quite a lot about the design and implementation of these.
As I mentioned in the introduction to the interview, I highly recomend that you read the following three links about Kafka, its design and uses:

Jay also gave a few excellent talks about Kafka that explain why it was created and what are its uses:
