Interview with Jesper Louis Andersen about Erlang, Haskell, OCaml, Go, Idris, the JVM, software and…
In this occasion we interviewed Jesper Louis Andersen, a type theorist with lot of practical knowledge and experience. His blog (you should…

Interview with Jesper Louis Andersen about Erlang, Haskell, OCaml, Go, Idris, the JVM, software and protocol design — PART I
In this occasion we interviewed Jesper Louis Andersen, a type theorist with lot of practical knowledge and experience. His blog (you should also check his old blog, you will find a lot of good things over there) and code (specially things like safetyvalve and fuse) have been a big inspiration to me. That is why I published the interview in two parts: I had too many questions for him. I hope you enjoy reading his answers as much as I did.

I published part II of the interview. Check it out!
Your reply to the picture that is below was:
The typical applications I write in Erlang have 3–4 functions above it in the call stack
Modern comfortable programming language #java:
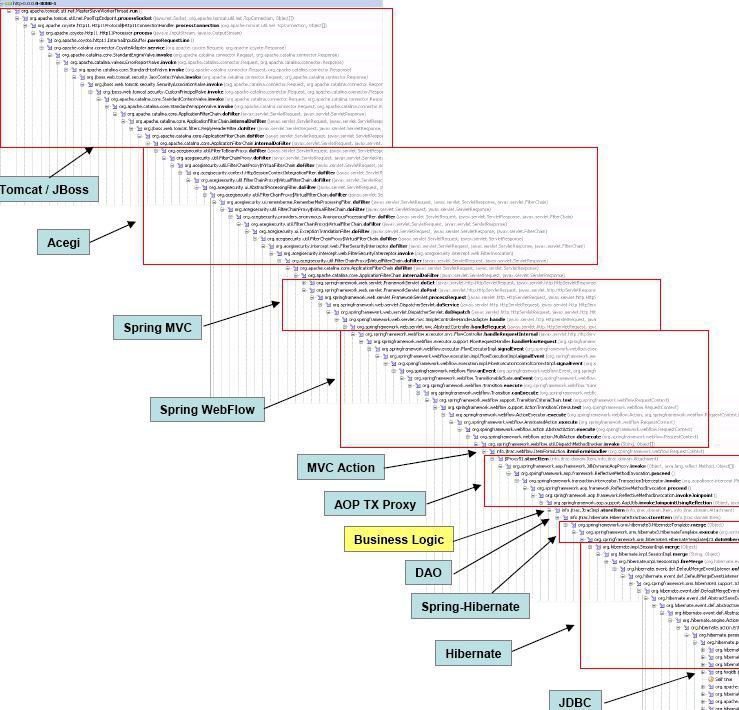
Why is it so? Why this is not the case in most OOP languages?
It is not really an artifact of OOP-style languages as much as it is an artifact of how we develop software. In biology, it has been observed solutions are usually not rewriting code, but rather patching code. Imagine a world where we are more inclined to build on top of what we already have rather than go down and rewrite older parts. I think each new generation of programmers tend to add a layer on top of what we already have, mostly to put their mark on programming and to simplify and abstract the parts of the lower levels which are in common use while also hiding the rare parts. What you get is the deep call stack. Another similar view would be in geology where you can see older layers and go back in time to older periods. Much of the Java stack has this in it.
Erlang is no different, but from the outset, small-community languages are less susceptible to patching. Especially if it is easy to rewrite code, which means an itch can be scratched by writing something new, rather than building on top of what others did. What brings the call stack down to 3–4 frames, however, are processes. In an Erlang-system a typical web request is served by cooperation of 3–4 processes, each of those having a call stack. Add them all together, and you approach the above size, but in isolation, they are small. An eventual error will result in a crash report with 3 things in it: the backtrace, the state before the process crashed and the incoming message which made it crash. The reason we have the original state is because of functional programming: every data structure is persistent, so we can version it. Usually this is enough to quickly isolate and figure out where the error is and what went wrong.
You tweeted:
“Lets talk agile: The ultimate agile language is one in which you can deliver working code quickly, which is also maintainable. Hence there are only a few agile languages in existence: Haskell, Ocaml and Erlang are 3. Go, Javascript, Python and the rest lacks the necessary abstractions to be regarded as agile. You end up having to recode. However, the real solution is to stop doing agile. The idea is bullshit in the first place.”
Why Haskell, OCaml and Erlang are the only agile languages?
If the waterfall model risks not building the right product, then agile risks not building the product right. I’m very fond of Erlang creator Mike Williams point: “If you don’t make experiments before starting a project, then your whole project will be an experiment”. My hunch is what a lot of Agile process misses is that you need to experiment before you build.
If we instead ask about prototyping, then we need a programming language with certain traits. The team is usually small, so we need an expressive language, and we need to address the core kernel of the system in isolation, first. We don’t need a lot of interfacing to foreign systems and in general we won’t care too much if the system we build is fast. Also, we usually won’t need to operate the prototype in production, since it is simply a proof of concept.
From a perspective of rapid prototyping and proof-of-concept development, functional languages tend to have an edge over imperative ones. Their higher level and expressivity allows more to be said succinctly, in fewer lines of code. They also tend to describe data structures and algorithms in ways that are clearer, which helps understanding of the problem space.
In turn, since agile values the minimum viable product, moving fast and making experiments, then you need languages in which it is easy to experiment with the unknown ideas many agile projects face. In languages such as Haskell, Erlang and OCaml you can often iterate over far more designs in a limited time window. Thus you can carry out more experiments and this often leads to a better product, even if the final product is not even written in a functional language. In general I feel we value experimentation too little. Build it, throw it away, and rewrite with the new knowledge.
What do you think about Clojure?
Sadly, my experience with Clojure is limited to carrying out a set of Koans in the language, and I have not ever used it for anything serious work. I must admit I don’t find the language especially compelling, and in general I don’t find Lisp-dialects interesting. My language roots are closer to Standard ML, which may be the reason it did not catch my interest when I finally tried toying with Scheme and Common Lisp.
That said, people are doing lots of outright amazing stuff in Clojure. I think the Datomic project is genuinely interesting as a database system. And the work Kyle Kingsbury has done with his “Jepsen” framework and his “Knossos” linearizability checker in Clojure is solid work. I’m also following David Nolen’s work with interest. But I’m pretty sure the language isn’t “for me”.
You tweeted:
Functional programming semantics are far more important than static typing for removing errors from programs.
Why? Could you elaborate?
I’ve somewhat alluded to this before, but never in more than 140 characters. In an imperative program a function depends on two things: the parameters it is passed and also the current state of the machine store. In a functional language, only the former matters. The consequence of this choice if far reaching:
One, the state space we have to reason about as human beings is far smaller for FP, which makes it harder to make a programming mistake. Two, we can test functions in isolation and be rather confident we have covered the functions execution well. Three, data processing is inductive in nature, recursing over the structure of data rather than manipulating the store from afar. The programming is closer to a proof by induction, which force the programmer to handle corner cases rigorously.
The ease of reasoning also comes into play once you have found a bug. It is often easier to figure out what the program is doing wrong just by taking a close look. It is rare you need to attach a debugger, which you can’t in a concurrent and/or distributed system where some parts are outside of your direct control.
When you add typing to the above, you obtain another dimension where your system is (automatically) checked for additional rigor. But I often find people forget how much power there is to be had just by functional programming on its own, with no regard to types. From my own experience, functional programs tend to have an order of magnitude fewer errors than imperative counterpart programs, especially when these are subtle corner-case errors, types or not. Naturally, types + functional programming help even more. But had I the choice between imperative programming with types or functional without, I know what I’d pick without hesitation.
What is your opinion regarding dependent types like the one Idris has?
I have not studied Idris very much yet, but I did some work in Agda and Coq, which both employs dependent types, albeit the type theory is subtly different between all of them. I’ve deliberately been pushing it ahead of me for a while, like I also have done with Rust. Mostly because I’d like them to settle down and mature a bit more before I start looking into them. I’d probably start looking around 2017 on both. From a research perspective, Idris is extremely important. We need to explore this area more for real world programs as well, and having a language designed for programs rather than proof-assistance is fairly important. Of course, one would like to see a more mature language, but one has to understand how much is being sunk into Idris to make this happen currently.
I’m not yet entirely convinced we necessarily want to add dependent types to mainstream languages in its full form. Perhaps it turns out we’d rather want a simpler type system in some areas in order to extend it along other dimensions. I’m somewhat interested in the Curry-Howard correspondence between distributed programming and epistemic logic for instance. And it is not a priori clear we even understand what it means to marry dependent types to such a beast. We may have to cut the cake differently in order to understand the type-level interactions.
Don’t you think that OCaml and Go compete for the same space? What has been your experience with the two languages and how do you think they compare?
If you squint your eyes hard enough, OCaml is an imperative language on top of which you added a lambda calculus. Or it is a lambda calculus with primitive operations for imperative execution. Either way, Go and OCaml are very much alike in the core: both are garbage collected, and natively compiled languages. They tend to provide execution speed in the same ballpark: usually they are in the same order of magnitude when it comes to executing programs.
What sets the two languages apart is the underlying ideology of how to design a programming language. Go is a modest cleanup of the C semantics on top of which you add channels, goroutines and interfaces. OCaml is a programming language in the tradition of Milners Meta-Language (ML), drawing inspiration from several sources including Haskell and Standard ML, among others.
Go usually opts for simplicity and separation of features into a small basis. The language is specifically addressing concerns when programming in the large. This yields programs which are highly coherent because the programmer have relatively few abstraction tools at their disposal. In addition, the interface concept in Go is implicit, which means you have less need to alter other parts of the system. In a large setting with 100s of programmers, altering code someone else “owns” is usually measured in days, whereas local alterations takes hours. So the time lost on lower abstraction can be deceiving.
The simple coherent design of Go also fosters fast compilation with little to no abstraction overhead. It doesn’t matter what abstractions you use, your program will usually compile fast and it will be pretty obvious what the performance behavior of the program is. Fast compilation speed matters in large settings because waiting on the compiler is often wasted time[*]
Russ Cox noted that some abstractions, generics for instance, makes a trade-off between putting the onus on the programmer, the compiler or the execution speed. Leave out generics and the programmer has to work around it. Add generics, and the compiler has to do more work in the compilation phase. Or abstract away generics by a boxing construction, which affects execution speed. Go opts for the first of these.
OCaml contrasts heavily. From an abstraction perspective, it leaves Go in the dust, and supports so much more efficient use of the programmers time. The compiler is also relatively fast and it handles the added abstraction well, though at the current time there is an overhead to the abstraction use. In the notion of Cox, the current version of OCaml (4.02) sacrifices execution speed in some cases. The new FLambda IR in OCaml 4.03, shifts this onus around and puts more into the compiler[0].
Another important dividing factor is the current lack of a proper Multicore support in OCaml, which also means the lack of a proper concurrency runtime built-in by default. In OCaml, you have to rely on a system such as LWT or Async to achieve the same as goroutines do in Go. And the fact there is two, means everyone has to support both for their libraries. The situation is far from perfect.
I usually grab OCaml for problems which have certain traits. Symbolic manipulation is one thing at which OCaml excels because it has proper algebraic datatypes. Thus, I would never write a compiler or proof assistant in something else. Programs generating programs is another area in which OCaml excels. Finally, problems which have embarrassingly parallel structure can easily be handled by just spawning more OS processes in OCaml, and the cogen of OCaml is quite efficient.
I usually write Go for simple brute-force programs where the interactions are not very complex and there is a simple channel network inside the program. I avoid it for anything with complex interactions, because the simplicity of the language often gets in the way. But some problems have the virtue of being simple by construction, which makes Go a really good language.
Personally, I prefer the OCaml ideology. Add abstractions to the language, build a powerful module system, with functors, in which you can program in the large by β-reducing modules into one another. And use the compiler and computer as a sacrifice to pay for this additional abstraction. Those programs are easier to maintain, and easier to recombine.
Go and OCaml are best used for the programs where there is a part of the program which is heavily CPU-bound and you are not memory bound. The vast majority of the programs I write have little to no need to run on a tight CPU-schedule and there I usually just write them in Erlang. If you are bound by memory, you often end up in situations where the gain of dropping to OCaml or Go is small. And if you are bound by outside interaction, disk or network, there is almost no gain.
[*] Fast compilation and linking speed are two major reasons I like Erlang too.
[0] A worthwhile aside: The MLton Standard ML compiler takes this to an extreme by compiling all of the program in one fell swoop. Thus, it is able to perform whole-program analysis and optimization with perfect knowledge of the program. This makes a lot of the abstractions free, but the price is long compilation times.
In a great post where you explained the drawbacks of JSON and REST HTTP APIS you also wrote:
“We need to go back to our roots and start building protocols again. This change will never come from a large company. It has to rely on an open tinkerer culture. We need well-defined protocols and multiple implementations of these. Protocol design is quickly becoming a lost art. Rather, people are satiated with “APIs” to the point where they can’t recover.
We need de-centralization. The internet is built on the idea of end-to-end interaction between machines. The current state is more of a client/server infrastructure in which few central entities drive the status quo.
We need distribution. If we rely on big players, we tie ourselves to their solutions. This will be a bane going forward as we build infrastructure around vendors only interesting in lock-in.
And finally, we need education. A lot of the current “protocol design” is so bad compared to what can be found in old RFCs. If you want to implement something new, you need to study the past a lot before you build it. If you reject an old idea, you need to explain why. If you reinvent an old idea, you need to know you reinvented it and what happened historically for that idea not to catch on.”
Could you give us some recommendations of RFC, books, articles to read and exercises to do learn how to design protocols?
Good protocol design is an art form. The goal is produce protocols which are simple to implement, are hard to implement wrong and have future extensibility. Take the TCP protocol for instance. You can implement it in hardware as a simple stop-and-go protocol, ignoring everything about sliding windows. This is a correct and valid implementation of the protocol, though it will be slow. Once that works, you can add layers on top which makes the protocol faster. In addition to the RFCs for TCP, James E. White’s RFCs, 707 and 708, are dear to my heart. They were written in 1976, and they handle a lot of problems we still have to this day: how will distributed machines communicate.
The BitTorrent protocol deserves mention as well. It defines how clients communicate, but it gives relatively few rules about how a client is supposed to implement their behavior. Once you set forth and start implementing the protocol however, you find there is only one true way of doing each part. So that could be left out of the specification. Instead, a minimal viable protocol is given, and the details can be altered as you go along. But also note how the original BT protocol used a Bit-array of 64 bits in the handshake rendezvous in order to negotiate what additional features were supported. This was later replaced with a fully extensible system because it proved to be inadequate. Whenever you see such patches of the protocol design, think about how it could have been avoided in the first place.
Another incredibly well-designed protocol is the 9p protocol from Plan9. And it is generic enough it can be adapted to a lot of other situations as well. It implements many good ideas, like out-of-order messaging, proper multiplexing of messages on one channel, requests initiated from both ends of the connection, and so on.
The general advice is to cut out any part which nominates how the peer should behave itself internally. You need to maximize the freedom of the implementer and only establish the basis for communication. Cut cut cut. Leave out everything which will not destroy the coherency and internal consistency of the protocol. Layer the protocol and push things into separate layers. A layered protocol is much easier to reason about formally, and you better be doing so though either Model Checking or quickchecking the protocol internals.
One should read the critiques of HTTP/2.0 and how we got there from HTTP/1.1. The protocol suffers from some rushed work, sadly. Read some of the simpler alternative approaches. As an example the PUSH message from Server to Client in HTTP/2.0 grows out of White’s observation in RFC707: both peers in a protocol needs to be able to initiate communication. But HTTP is skewed, like most RPC, since all communication is initiated from the client toward the server.
A good approach is that of Roy T. Fielding — define what constraints you need, and then squeeze hard until the minimal protocol comes out. That is, start by defining a large framing of what you need your protocol to do and then create a protocol with those properties. TCP is defined by its constraints of being a stream protocol, connection oriented and without data loss. ZeroMQ is a message channel, connection oriented, without data loss. UDP are message oriented, datagram oriented, with loss. SCTP is …, and so on.
Protocols are far better than APIs because they invite multiple competing implementations of the same thing. They debug themselves over time by virtue of non-interaction between peers. And they open up the design space, rather than closing it down. In a distributed world, we should not be slaves to API designs by large mega-corporations, but be masters of the protocols.
