Interview with Osvaldo Martin about Bayesian Analysis with Python
Like our previous interviewee Osvaldo Martin is one of the developers of PyMC3 and ArviZ. He is a researcher specialized in Bayesian…

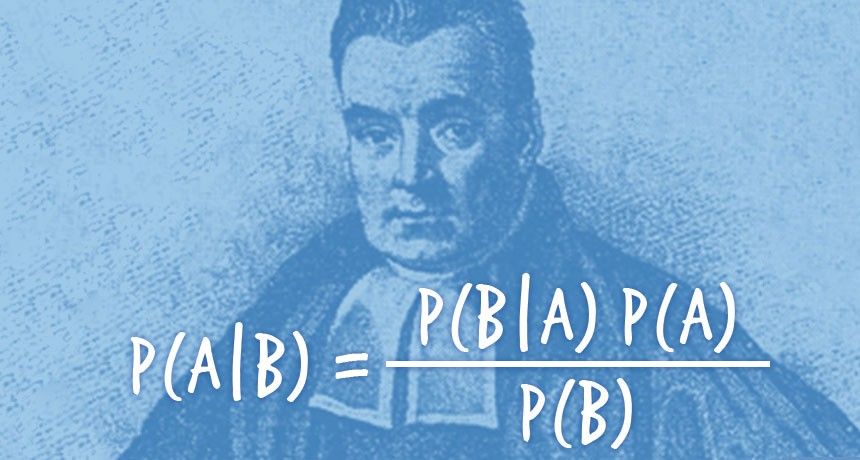
Like our previous interviewee Osvaldo Martin is one of the developers of PyMC3 and ArviZ. He is a researcher specialized in Bayesian statistics and data science. He will be speaking at our BuzzConf this year. I hope you like this interview as much as we did!
Can you tell us how data analysis has improved over the years?
This is not a simple question to answer, specially if we take into account that we have been doing data analysis from ancient times. The analysis of astronomical data has a long tradition it even predates (modern) science. For most of our history it was motivated by the many different religious liturgies we have invented over the centuries and the more grounded need of improving and controlling the food production. Fast-forwarding thousand of years one can argue that the data-driven studies of astronomers like Tycho Brahe had a decisive impact on setting up the scientific revolution. Astronomy and astrology were not fully separated by that time, but Brahe, based on his observations and experience already thought that astrologists were just charlatans and he maintains that the planets and stars have null influence over the human affairs. If that’s not a Data Scientist, who is?
So the “big thing” we are living now is not that we suddenly realize data is important, we have already known that for centuries, the difference is that now we have tons of available data from scientific disciplines like Biology and Astronomy, just to name two, and from daily interactions with streaming platforms, social networks, cell phones, and sensors all around us. Computers have made this possible by increasing our capacity to storage, process and transmits information by several order of magnitude, and perhaps equally important computers has also changed the way we ask questions and provide answers. There is a whole array of new methods to analyze and generate data, that are impractical without computers. Indeed, the modern practice and development of Bayesian methods have been profoundly influenced by the computers and computational methods up to the point that modern Bayesian statistics IS computational statistics. The only reason we are talking now about probabilistic programming, Machine Learning and Data Science is because we have cheap and fast computers.
Can you tell us in brief how PyMC3 and ArviZ help with Bayesian Analysis?
PyMC3 is a probabilistic programming language offering two main components: a very clear syntax to define probabilistic models and a powerful set of methods to solve those models, mainly Markov Chain Monte Carlo and Variational Inference. Ideally the methods to solve probabilistic models should be Universal in the sense that they should be able to solve any valid probabilistic model. Unfortunately, even when current methods are very powerful they do not always work as we like, some models are still very difficult or slow to solve. Thus an important step in Bayesian Analysis is to check that inference was done properly. And this is one the motivations for creating ArviZ, a Python package for exploratory analysis of Bayesian models. ArviZ Includes functions for posterior analysis, sample diagnostics, model checking, and comparison. ArviZ works hand-in-hand with PyMC3, and other probabilistic programming language, like PyStan, emcee, Pyro, etc. Where the aim of the probabilistic programming languages is to make it easy to build and solve Bayesian models, the aim of the ArviZ library is to make it easy to process and analyze the results from the Bayesian models.
Can you explain some of the main concepts of Bayesian Analysis?
Bayesian analysis can be summarized in just two concepts. Use probability distributions to represents the uncertainty in your model parameters. Then use Bayes theorem to update those probabilities given the data you have. All the rest derives from these two main concepts. Other concepts that are important to the practice of Bayesian Analysis are shared with other modeling approaches, like evaluating if models make sense by comparing their output against the data and the available domain-knowledge.
Why do you like working with data?
I am not sure I “like” working with data, working with data is hard, data collection, data wrangling, cleaning and processing is generally time consuming. Data per se is not important what really matters is understanding phenomena, solving problems and designing better tools to solve problems. What happens is that data is essential to all these tasks. To answer any question in a scientific way you will need data at some point, for some problems you can progress a lot with just theory, but eventually you will need some data. The only scientific discipline that can avoid using data is pure mathematics. And for that reason many people do not think that mathematics is a scientific discipline, or if so they classify it as a logical science and not a factual one.
Everyone is talking about the data deluge and thus is easy to miss that data is produced by someone and that producing data is not always easy or cheap. Even when we have access to pre-existing data it may need further processing or it may not be suitable to answer our questions and thus we may need to generate data from scratch. In general, answering specific questions requires generating specific data under specific conditions. Just a few years ago many computational biologists and bioinformaticians believed that by extracting biological information from scientific journals and databases we will be able to build very reliable models of the cell. It turns out that while this is a good idea, is not that easy as its sounds and not applicable to every question. Papers are behind paywalls, written in formats not that easy to analyze programatically, experiments are performed under so many different conditions that integrating the information coherently is closer to a bad breakup than a romantic dinner, some experimental results are too noisy or the experimental design is flawed, observations can be contradictory, information in databases need to be further curated, etc.
To many people Data Science have put “data” in the spotlight, but science has always been data-driven. Charles Darwin was responsible from one of the most elegant scientific theories, and one of the most misrepresented ones. He spent years and years collecting data, not for the sake of having data but to try to make sense of the diversity and complexity of living organisms. Nowadays evolutionary biologists still spend a lot of time producing and gathering data from carefully designed observations, experiments and simulations in order to refine evolutionary ideas.
What are the advantages and disadvantages of using Python over other languages for data analysis?
One of the reasons I use Python is that it is a general purpose language, and while I spend a lot of time on data-analysis related stuff I also use Python to solve other types of problems. I learned to program during my PhD without formal training but with the help of great books like Think Python by Allen Downey and A Primer on Scientific Programming with Python by Hans Petter Langtangen, and also helped in many different ways by a large, welcoming and enthusiastic Python community.
At the time of my PhD most of my “coding” was about automating boring stuff and gluing specific scientific packages in order to perform molecular simulations and very very simple data-analysis problems. I used to do that using a collections of poorly documented (and probably poorly written) bash scripts. With the time this approach turns to be too restrictive, so I tried to learn Fortran and C, but I found them overcomplicated for most of the tasks I wanted to solve at the moment, and only very useful for a subsets of them… until I find Python! As someone said Python is not the best programming language for almost any task but is good enough for most of them as I would discover with the pass of time and with every new project that involved Python. One super tedious task for me at that moment was updating plots. I used a software with a GUI (and open source clone of a reeeeeally expensive proprietary scientific plotting software). Updating plots after re-running a simulation or noticing a mistake or getting feedback from my advisors or peers was a lot of work. Somehow, I did not remember the exact moment I found matplotlib, that was a deal-breaker for me and one of the reasons to learn even more Python.
Another epiphany was when I re-wrote a small piece of software a colleague kindly passed to me. Like me, my colleague was a non-computer-scientist. This code was a collection of bash scripts and a Fortran main program. I started with the bash scripts, instead of running several bash scripts I unified all of them into a collection of coherent Python functions. This already make my workflow easier and I was already super-happy, then I decide to change the Fortran code, at first this was mainly an exercise to challenge myself to learn more NumPy and Scipy. After many attempts to get this right (I never truly learned Fortran) I got a working Python version of the code, this code was not only much more shorter, easier to read and more modular, but to my surprise it was also 10x faster! Most of the speed-up come by replacing a lot of Fortran code with a SciPy call and a couple of NumPy array operations. And this was an important lesson to me. Do not re-invent the wheel, there are many specialized, well-tested, efficient routines out there, use them! Because while Python is slow not being proficient programmer in a fast language like Fortran or C can be even slower!
What aspects of doing Bayesian Analysis with Python do you feel are tricky to get past?
For newcomers getting a fully functional Python environment can sometimes be tricky. Anaconda (a scientific Python distribution) and conda (a package manager) have helped a lot to get things installed properly, specially for Windows users.
When I show PyMC3 code to people most of them seem surprised by how much you can do with a few lines of codes. I even get responses like “that’s not programming” which I totally agree is just using a programming language to give instructions to a computer and get things done ;-) The challenge when using PyMC3 is then not so much on the programming-side but on the mental-modeling side, at first most people has problems figuring out how to express they problems in terms of a probabilistic model. This is a matter of practice and the creative part of the job. In the book I tried to show many examples of different models to help ease this transition to thinking probabilistically. This is something that needs practice, knowing that most pop-songs are built from the same chord progression of 3 to 4 chords that’s not automatically makes you a pop-star.
Your take on the data analysis environment with regards to innovations in it, the knowledge and skills gap, and software development. How do you think the tech landscape is changing?
My impression is that we now have something that was completely unimagined just a couple of decades ago: the popularization of very powerful computer methods. One of the side effects of the computer revolution is that any person with a modest understanding of a programming language like Python now has access to a plethora of powerful computational methods for data analysis, simulations, and other complex tasks. I am totally in favor of this, is one of my motivation to work on Open Source Software projects and to give free courses at the University. But I also recognize that this should be an invitation to us, as a community, to be extra careful about these methods not only to be able to apply them correctly from a technical point of view and to avoid making false claims but also from an ethical and democratic perspective. Otherwise we face the risk of giving too much control over important decisions to an increasingly reduced group of rich and powerful people and corporations, something that I am afraid is already happening and with disastrous consequences for those of us that not are part of the super-rich club. To turn this popularization of methods into a true democratization we need not only to make the methods accessible we also need to make other resources widely available. If the majority of the data generating processes, the data itself and the most powerful hardware is controlled by a small group then, we are not aiming for a true democracy we are just spending a lot of resources into training a high skilled work-force to serve the interest of a few and that is just a technocratic version of an oligarchy.
