Stumpy: unleashing the power of the matrix profile for time series analysis
An interview with Stumpy creator Sean Law

An interview with Stumpy creator Sean Law
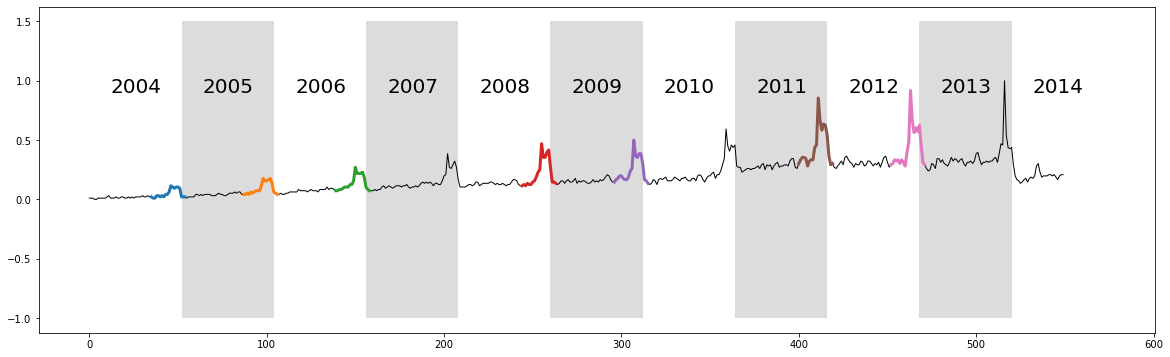
In the mid-20th century, the Information Age started. Every day an astonishing amount of data is created and analyzing it in an efficient way requires computational tools that combine novel and clever approaches that benefit from cutting edge technology.
Time series are a particular kind of data: the points measured are related by time, and analyzing them can often become quite difficult because time is not just like any other variable. More traditional methods like ARIMA or machine learning methods like LSTM can quickly become computationally inefficient as the amount of points increase, and sometimes they can be too elaborate for simple results such as finding overall patterns in the data, not to mention the complications arising when finding more complex patterns in the data is the final goal.
Stumpy is a library for analyzing time series, that tries to address the problems that appear when working with this kind of data. By design, Stumpy high performance, simplicity, and to employ general purpose approaches for extracting meaningful information. We interviewed the team to learn more about this promising project.

What is STUMPY? What are the goals of the project?
Numerous classical methods exist for understanding and analyzing time series data, such as data visualization, summary statistics, ARIMA modeling, Markov modeling, anomaly detection, forecasting, machine learning, deep learning, etc. The list goes on. However, when a data practitioner is presented with new or unfamiliar time series data, many of the aforementioned approaches often fail to uncover any significant pattern, anomaly, or unique observation since it isn’t known, a priori, whether or not an interesting insight even exists. Of course, if a behavior is found to be conserved within your time series (though, this may not always be true), then there must have been a reason why it was conserved and teasing out those reasons or causes can often be very useful. Note that with time series analysis we are rarely interested in single point statistics (i.e., global max, global min, etc) and, instead, it is more valuable to discover interesting “subsequences” (i.e., a continuous run of values along your time series with a preset length). So, when starting with time series analysis, one should really be asking:
- Do any conserved behaviors (i.e., repeating subsequences) exist in my time series data?
- If there are conserved behaviors, what are they and where are they?
A naive but straightforward approach that can help answer these questions (covered in more detail here) could involve comparing the Euclidean distance for every subsequence within the time series in a pairwise fashion in order to identify subsequences that are either highly conserved or exceptionally rare. This seems intuitive at first and it provides an exact solution to our problem but, as the size of the dataset increases (>10,000 data points), this brute force search can quickly become computationally intractable and reveals why approximate solutions (i.e., allowing for false positives and false negatives) or less interpretable solutions (above) have prevailed. Recently, independent research conducted at UC Riverside has spawned a collection of brand new ideas and they have developed scalable algorithms that directly addresses this hard computational problem. However, the knowledge and capabilities that have been transferred to the scientific Python community has been limited.
And so, STUMPY was born. STUMPY is a powerful and scalable Python package that faithfully reproduces the aforementioned academic work and, at its core, efficiently computes something called a “matrix profile”, which can be used for a variety of time series data mining tasks. Essentially, a matrix profile is a vector that stores the Euclidean distance (and index location) between each subsequence within a time series and its nearest neighbor. And, with 100% code coverage and multi-CPU/multi-GPU support out of the box, the goal of STUMPY is to provide a highly reliable and user-friendly interface for modern time series analysis that can quickly and easily scale up to accommodate your ever-growing data needs.
What kind of time series analysis can be done with Stumpy? In what fields do you think it will help the most?
As mentioned above, STUMPY is focused on efficiently computing a simple-to-interpret but highly useful data structure called the “matrix profile”. Earlier, Eamonn Keogh, one of the original academic researchers, claimed that “Given the matrix profile, most time series data mining problems are easy or trivial to solve in a few lines of code.” In fact, Keogh and his colleagues have since published over 20 papers demonstrating the many things that can be done once you’ve computed the matrix profile and, below, are a just few examples:
- Motif discovery — identify conserved subsequences (related to pattern recognition)
- Discord discovery — uncover subsequences that are poorly conserved (related to anomaly detection)
- Time series chains — find related patterns that are evolving monotonically over time (related to forecasting)
- Semantic segmentation — automatically determine regime changes within your time series data (related to change point detection)
- Streaming data analysis
- Multi-dimensional matrix profiles
- Time series clustering
- And more…
One of the benefits of computing matrix profiles with STUMPY is that it is 100% domain agnostic. This means that it is completely generalizable and can be applied in any field where you need to analyze continuous sequential data! In addition to the previously published examples, STUMPY has been applied in analyzing the stock market, bettering server uptime and resiliency, investigating call center conversation flow, understanding IoT sensor data, improving cryptocurrency model predictions, and stabilizing ion acceleration at CERN, just to name a few. Today, time series data is ubiquitous in both academia as well as industry and so we believe that STUMPY is a new tool that is extremely well positioned to help researchers and data scientists explore their data in a systematic and focused way and, hopefully, allow them to discover new insights with much less frustration and time spent. If you already have Python installed then you should be able to get started with STUMPY in less time than it takes for you to make a cup of coffee.
What are the benefits of computing the matrix profile in the context of analyzing a time series? What are the advantages over other methods?
Matrix profiles are simple, intuitive, and interpretable. Basically, if you understand what Pythagorean theorem is then you’re all set! Whereas with other methods, if you step away from the analysis for six months and then come back to it, you often have to perform a lot of mental gymnastics in order to remember and understand what was going on. With a single line of STUMPY code, you can compute your matrix profile and quickly identify motifs (conserved patterns) and discords (potential anomalies) by looking at the minima and maxima, respectively. From there, a slew of rapid post-analyses can be performed using the matrix profile and the subsequent results can help you develop further hypotheses and questions about your data. Additionally, unlike other methods which may be riddled with false positives and false negatives, matrix profiles are exact and don’t require any “training” in order to find patterns. It just works right out-of-the-box!
What is the general criteria when choosing a window size? Is there some indicator to look up when analysing a time series?
That’s a good question. Usually, the window size (i.e., the length of your subsequence or sliding window) should be chosen to be large enough to encompass a potential pattern. This usually requires a little bit of domain knowledge but the academic researchers have found that matrix profiles are not so sensitive to the choice of the window size so long as it isn’t smaller than the subsequence pattern. So, being in the rough ballpark is usually enough. However, since matrix profiles are pretty fast and cheap to compute, your best bet is to simply try several different window sizes, perhaps, by repeatedly doubling your window size and observing where there may be conserved minima/maxima across the set of matrix profiles. The academic researchers have also published a paper (which you can download here) detailing a similar approach called a “pan matrix profile” that can help narrow down the search space. So, look out for this new STUMPY feature in an upcoming release!
What is semantic segmentation in the context of time series? What were the problems in the past with this method and how do you solve them?
In the context of time series, “semantic segmentation” is “the division of a time series into internally consistent areas/regimes” or, sometimes, you can think of it as a “special type of clustering with the additional constraint that the elements in each cluster are contiguous in time”. Basically, if you have a time series where the values are repeating periodically within some range and then, in response to some external change or event, the time series shifts into another mostly periodic range so that you are left with two distinct “regimes”, then semantic segmentation may be useful for helping you identify the boundary in between the regimes. Now, methods like “change point detection” exist for detecting changes in various statistical properties of the time series (i.e., the mean or variance) but, fundamentally, we are interested in regimens which are defined by changes in the shapes of the time series subsequences, which can change without any obvious effect on the statistical properties. And this is where matrix profiles come into play. By simply using the information stored within your matrix profile, you can automatically identify and label these boundary regions in a systematic way. You can learn more in this illustrative STUMPY tutorial.
How does the sampling rate affect the analysis of a time series? How often are important patterns hidden because of a bad sampling method?
In general, sampling rate is quite important but it is often independent of the analysis method. If you have a conserved pattern that spans a full minute (i.e., it is a unique shape that is captured within 60 data points spaced one second apart) but you only collect a single aggregate data point once every hour, then it is impossible for any method to discover this pattern. Conversely, if you collect a data point once every microsecond then you might run out of storage space or lack the ability to analyze this large data set after 5 years. Unfortunately, in either case, having the best algorithms and the fastest hardware will not help you fix poor sampling. Or, as they say, “garbage in, garbage out”.
STUMPED is the distributed version of STUMP and it is implemented using Dask. Why have you chosen Dask over other solutions to implement STUMPED?
As a research scientist, one of my pet peeves is software that is slow or that takes way too much time and effort to install. So, it was imperative for STUMPY to have minimal dependencies, be easy to install, and also be fast and scalable. Initially, when we prototyped STUMPY, everything was written using NumPy and SciPy and this worked well for time series that contained around 10K data points. However, we noticed that not all of the threads on our machine were being used (due to the GIL) and things started to take forever as we increased the length of our time series. At the time, Cython was a popular option for releasing the GIL but it seemed really hard to maintain from a packaging perspective and the coding style never felt “Pythonic”. In contrast, we had starting hearing a lot of great things about Numba’s ability to JIT-compile Python code into performant machine code and so, within two days, we were able to parallelize STUMPY using Numba and leverage all of the compute power available on our local server. For data scientists, this is great and usually sufficient for small to medium-sized data sets but, naturally, we starting thinking about distributed computing. Dask is a wonderful Python package that offers scalable analytics, can be easily distributed to over a thousand servers, and has a large user community. Additionally, we knew that Dask interoperated well with Numba and so, within five days, we were able to go from a single server to distributing our matrix profile computation across a 32 server Dask cluster. While other solutions currently exist for distributed computing, we really liked that Dask was lightweight, heavily battle-tested, and was supported by knowledgeable maintainers who had the right vision. While STUMPY does not leverage Dask’s “big data collections” (i.e., parallel arrays and dataframes), the robust dynamic task scheduling used by STUMPY is well beyond experimental.
Was GPU compatibility challenging to integrate in the project?
This is a great question! In our journey, we carefully assessed the landscape and seriously considered the idea of using PyCUDA, CuPy, TensorFlow, PyTorch, or even writing raw CUDA kernels and interfacing it with Cython. However, these technologies can either be too hard to install, too low level and verbose, too difficult to maintain (or for others to contribute to), or their APIs are simply too unstable. Ultimately, the best solution for adding GPU support was right underneath our noses and we didn’t even need to add any additional dependencies! Because, luckily for us, Numba is also able to JIT-compile Python code to target GPUs. Of course, it is important to point out that since the programming paradigm for GPUs is quite different from CPUs, STUMPY has to maintain separate Python modules that target the different hardware and we’ve had to develop new and unique ways to ensure proper and thorough testing of our software. However, the massive performance benefits gained from leveraging GPUs and not having to switch from Python to writing CUDA is well worth the tradeoffs. If anybody tries to convince you that “Python is slow” then I’d highly recommend trying Numba and Dask as they can easily help take your Python performance scaling to the next level. If you are interested in computing matrix profiles with STUMPY using GPUs then please check out this Google Colab notebook.
Considering you have chosen Numba for optimizing and parallelizing computation, have you thought about using Julia in the future, which has built-in features for this tasks?
Julia has certainly grown over the years but its adoption has been slow and so we’ve yet to consider it as a viable option. However, given the amount of effort that we’ve put in to keeping our code base easy to read and digest, it shouldn’t be difficult to port STUMPY over to other languages and we’d certainly be open to sharing and collaborating in the future.
How do you justify the comparison between the benchmark using 256-CPUs (STUMPED.256) against the one using 16 GPUs (GPU-STUMP.DGX2), especially economically speaking?
The STUMPY README provides rough performance benchmarks but the point isn’t to debate whether GPUs are “faster” or “better suited” for computing matrix profiles than CPUs. If you have access to one or more GPUs, then you should definitely use them! However, if you don’t have access to top-of-the-line GPUs or national super computing clusters, STUMPY can still be useful. Benchmarks are always biased and outdated but our goal is to be transparent and to give people a clearer sense of how long their computation might take (depending on the size of their data) and what hardware resources they may need in order to realistically complete their analysis. Otherwise, the user should be able to make an informed decision as to whether or not STUMPY is suitable for their situation. For all intents and purposes, STUMPY is more than “fast enough” and, more importantly, it faithfully reproduces the academic work and users can feel confident that STUMPY can perform equally as well on better hardware and with larger data set! Thanks to Moore’s law, you don’t have to take our word for it. Give STUMPY a try and let us know what you think!
In the paper presenting the STOMP algorithms, an implementation in a seismologic dataset is shown, working with a really huge amount of data and analysing it within days. How near are we from real-time anomaly detection systems that analyse datasets as large at that scale?
To answer this question, one first needs to clearly define what is meant by “real-time”. Typically, this involves a situation where large amounts of data is being streamed in continuously and at a reasonably high frequency rate. Additionally, when discussing real-time analysis, it is important to identify how much data needs to be collected before the analysis can begin (i.e., is it one data point or do you need to collect 10 days worth of data before you can start) and it is also worth considering whether this is a sliding window analysis (i.e., where the oldest data point is removed as a new data point arrives). I can’t speak directly to the primary research but, in the 100 million data point seismology example, the dataset was actually recorded at 20 Hz and collected over 58 days but the the matrix profile was computed in just over 12 days. In that particular case, the speed of analysis (12 days) was actually faster than the speed of data collection (58 days) and, naturally, if you could initiate your analysis with less data then the matrix profile computation would require substantially less time as well. Of course, this feels more like a batch analysis than a streaming analysis but hopefully the point that we’re trying to make is clear. In fact, the academic researchers have published additional work on how to incrementally update your matrix profile on-the-fly as additional data points are streamed in. This streaming-friendly capability is currently available in STUMPY and more detail can be found in this STUMPY tutorial.
How do you think STUMPY will evolve? Do you have in mind new features to implement in the near future?
One of the co-founders of Explosion, Ines Montani, gave a wonderful talk at PyCon India 2019 titled “Let Them Write Code” where she identified that ‘Good tools help people do their work. You don’t have to do their work for them. Worst developer experiences: tools that want to be “fully integrated solution”’, which I think embodies our approach to developing STUMPY. We have purposely limited the scope of STUMPY and stayed laser-focused on making our code base rock solid, performant and well tested, and super user-friendly. While it may be tempting to over-simplify time series analysis and offer additional things like data cleaning or custom visualization tools all in one package, we want to enable all of our users to really think through their analysis approach rather than relying on a package to make false assumptions about their data, which is more than likely to be wrong anyways. To that extent, STUMPY has already achieved its goal in providing an efficient way for users to compute matrix profiles and that is scalable on a wide variety of hardware. Additionally, there has been a lot of interest in computing matrix profiles with non-normalized Euclidean distances (as opposed to z-normalized Euclidean distances) and so we’ve added a suite of new features that addresses these needs and you can check out our current backlog of feature enhancements on our public Github page. There is still a lot of work that needs to be done to socialize the matrix profile approach, to educate others through public talks and tutorials that use real-world examples, and to continue building and fostering a transparent and supportive community. Of course, this will take time and is easier said than done but we’re making progress everyday.
Are there any books you recommend reading on the topic?
Unfortunately, there aren’t any books on the topic yet but, for starters, readers may be interested in exploring the STUMPY tutorials or watching this STUMPY video (hosted by the Stitch Fix Algorithms team) as they provide a balanced mixture of background information, relevant context, and technical detail to help you develop the right intuition. Additionally, I strongly recommend skimming the plethora of articles published by Eamonn Keogh’s group. They’re actually a pleasure to read and I continually learn more each time I re-read these foundational papers.
Where can readers find you and where can they learn more about STUMPY?
I blog occasionally on my personal website but you can follow me on Twitter @seanmylaw and you can stay up-to-date on the development of STUMPY @stumpy_dev. Additionally, please post all of your STUMPY questions to our Github issues page as this will help ensure that all user questions are recorded and searchable by others. Also, we’re always looking for new contributors and, especially if you are a tech minority, we’d love to work together with you. And don’t forget to share STUMPY with all of your friends and colleagues and let us know how you are using STUMPY!
