The Road to Networking Stability

Stakers told us they want to switch between execution clients without friction, sometimes leaving a node off for several days before switching back. Over the last month we shipped a series of fixes across ethrex's P2P stack. Restarts are more reliable. Bandwidth consumption dropped by a meaningful factor on every node we run. Header downloads continue across imperfect peers, full sync recovers from edge cases without operator intervention, and a few RPC paths that used to drag on cold blocks now answer fast.
Each fix is small on its own; the systems they touch are not. For each topic, we walk through the technical context and how we picked the simplest solution with the smallest surface area.
1. Discovery pings: when peers ask too much about your neighbors, you may want to wait before answering
How execution clients find each other
Two execution clients have to find each other on a network of ~5–10k mostly-anonymous peers before they can exchange blocks or transactions over RLPx. The discv4 protocol specifies this behavior, a UDP-based variant of Kademlia that Ethereum nodes have used since Frontier, with discv5 layered alongside it. The shape follows standard Kademlia:
- Each node has a 256-bit identity derived from a secp256k1 public key.
- The node keeps a routing table of 256 k-buckets, each holding up to k = 16 contacts, indexed by XOR distance to its own ID. The spec is explicit about both numbers.
- A node sends
FindNode(target_id)to a known peer, which responds with up to 16 of its closest known contacts inNeighborspackets. Repeated lookups against random or specific targets fill the table.
The endpoint proof keeps this from being abusable. The discv4 spec says: "Neighbors replies should only be sent if the sender of FindNode has been verified by the endpoint proof procedure." Before you get FindNode responses out of a peer, you have to complete a recent Ping/Pong with it, and the peer keeps you marked as verified for 12 hours. Without this rule, anyone could spoof a source IP, send FindNode, and have the network fire 16-node Neighbors packets at the victim, turning Kademlia into a UDP amplifier. discv5 takes a different approach (the WHOAREYOU challenge-response), with the same goal: cryptographic proof that the other side owns the endpoint they claim.
The other piece is revalidation. The spec says little about it, only that when you insert a new contact into a full bucket, you ping the least-recently-seen entry and evict it if it doesn't reply. The spec mandates no periodic revalidation rate. Every client implements one anyway, because a routing table full of dead entries wastes lookups, and any contact older than 12 hours falls outside the endpoint-proof window so its FindNode requests get dropped.
The implementation choice each client makes is how aggressively to revalidate. Geth picks one random stale contact per ~1-second tick, a steady drip on the order of one ping per second total. Reth runs a 10-second cycle and at each tick collects all expired entries and pings up to 32 of them in a batch (re_ping_oldest in crates/net/discv4/src/lib.rs). Nethermind has no dedicated revalidation cycle; its DiscoveryApp runs a Kademlia lookup loop with adaptive backoff, and pings happen as a side effect of node-state transitions and bucket eviction challenges (NodeLifecycleManager.cs).
Two reasonable strategies at opposite extremes. ethrex's earlier design picked a different point on the spectrum, and we set out to improve the operational behaviour it produced.
Where the previous design produced traffic spikes
Two interacting properties of the older code drove most of the discv4 packet rate:
- Every
Neighborsresponse sent to ethrex, up to 16 nodes, triggered an immediatePingper node, on the rationale that we wanted those new contacts to be eligible for the next FindNode lookup as soon as possible. A singleFindNodewe sent fanned out to 16 outbound pings on the response, a 1:16 amplification of our own traffic. - The revalidation loop walked all stale contacts in a tight
forloop on every tick. With thousands of contacts, most of them outside the 12-hour endpoint-proof window at any given moment (we run most lookups during startup and rarely talk to most contacts again), every revalidation tick produced a burst of pings.
The first pass, #6394, pulled the per-neighbor ping out of handle_neighbors (crates/networking/p2p/discv4/server.rs). New contacts went through the regular revalidation loop instead of getting pinged on receipt of Neighbors. The same PR added a tracker so we accept Neighbors responses only for FindNode requests we sent, which closes an unsolicited-table-injection vector that the amplification fix alone wouldn't catch.
The same PR also lowered REVALIDATION_CHECK_INTERVAL from 12 hours to 30 seconds, on the reasoning that without immediate pings on arrival, the revalidation loop has to run often enough to ping new contacts within a reasonable window. That part needed a second pass: the revalidation loop was still doing the "ping every stale contact this tick" thing, so the bursty 1:16 amplification per FindNode turned into a steady wave every 30 seconds.
After a Hetzner warning on one of our servers, we improved our grafana metrics to better track outgoing traffic. In steady state we observed ~29k UDP packets/sec. Geth, by contrast, runs at roughly 1 ping/sec.
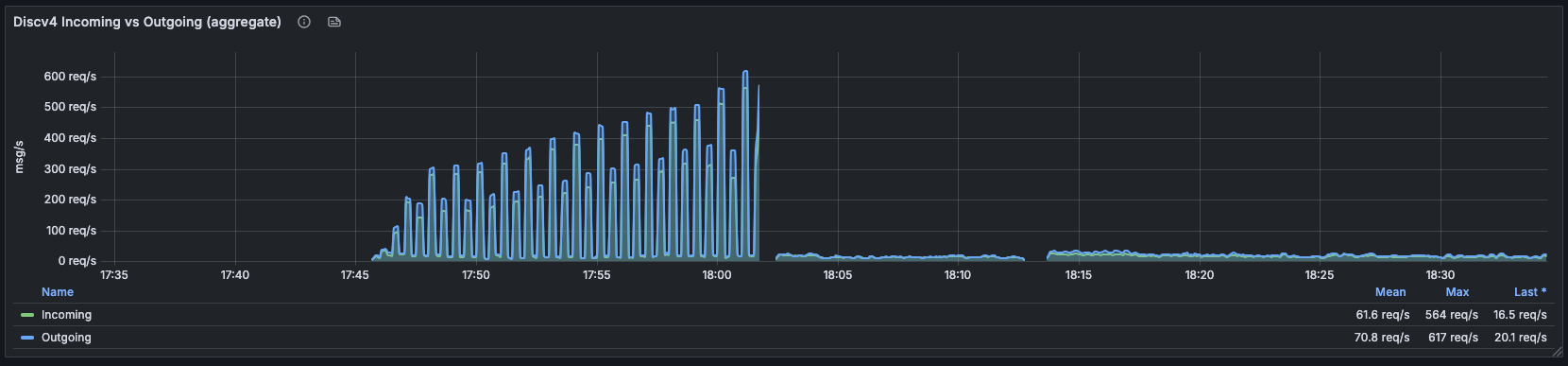
Discv4 incoming/outgoing aggregate. Pre-deploy regime: spikes climbing to 617 req/s every ~30s as the revalidation tick fired and every stale contact got a ping at once. Post-deploy at ~18:02: flat at the 16–20 req/s range, mean 61.6 / 70.8 req/s over the broader window.
The same fix landed in discv5, where the underlying issue was even more pronounced because the staleness threshold was set far too low (more on that below):
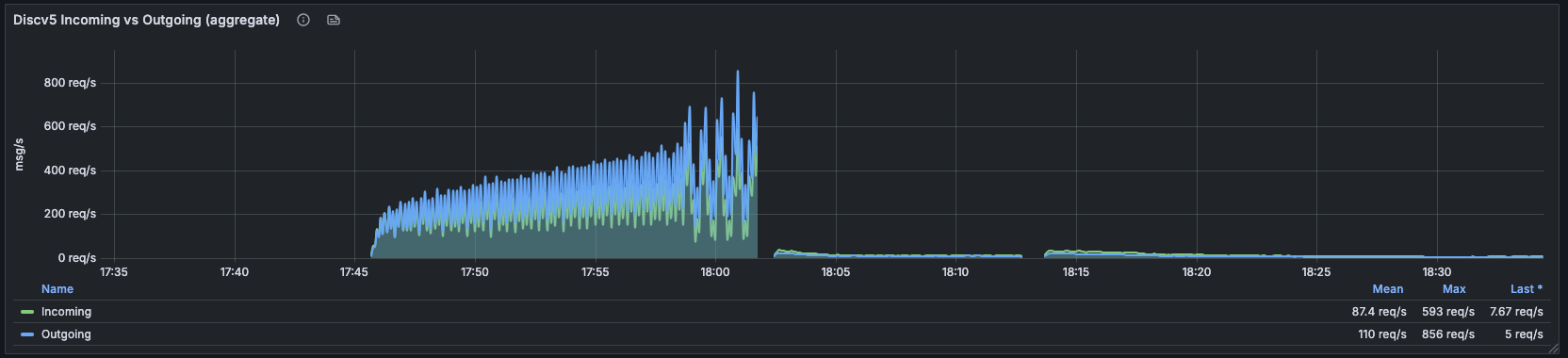
Discv5 incoming/outgoing aggregate. Pre-deploy: sustained 200–600 req/s with peaks up to 856 req/s outgoing. Post-deploy: collapses to single-digit req/s (mean over the window: 87.4 / 110 req/s; last reading: 7.67 / 5 req/s).
Less neighbors, please
#6438 was the proper fix:
- Reservoir-sampled revalidation. Each tick picks one eligible contact uniformly at random across all stale contacts over the filtered peer table, and pings only that one. The ping rate is now bounded by the cycle interval, not by table size, a property the previous code didn't have.
- Don't re-ping a contact that already has a ping in flight. Previously,
Contact::was_validated()checked only the timestamp of the last validation, so a contact whose ping was sent 100ms ago and was still in flight looked un-validated and the next cycle re-pinged it. Now the existing in-flight ping has to either land or time out (30 seconds) before we send another. - discv5 had its own bug. Its
REVALIDATION_INTERVAL(the staleness threshold, not the loop tick) sat at 30 seconds versus discv4's 12 hours, because we were using the revalidation interval to track pending contacts. Every discv5 contact looked stale forever and the loop never stopped finding work. Constant brought in line.
The names are easy to confuse, so to be explicit: REVALIDATION_CHECK_INTERVAL is how often the loop runs (1 second now); REVALIDATION_INTERVAL is how stale a contact has to be before we'd consider re-pinging it (12 hours, matching the endpoint-proof window). Each tick of the 1-second loop picks one stale contact and pings it, so the ping rate is bounded by the tick rate, not by how many stale contacts exist.
A more general pattern shows up here. The original "ping every neighbour we hear about" design was an eager validation strategy: solid and fast peer table construction, at the cost of a high packet rate. The naive way to fix it, pushing every unvalidated contact onto a queue and letting the revalidation loop drain it, has the opposite failure mode: the queue grows faster than you can drain it, with the worst pile-up right after startup when lookups are most intense, so it isn't bounded either. Reservoir sampling threads the needle. The queue is implicit (it's the routing table), and we drain it at a rate that doesn't depend on how full it is. Trading some convergence latency for a stable, bounded packet rate is the right tradeoff for a long-lived node, and other clients like geth do it this way for the same reason.
| Before #6394 | After #6394 (broken) | After #6438 | geth | reth | |
|---|---|---|---|---|---|
Pings per FindNode |
16 (amplified) | 0 | 0 | 0 | 0 |
| Revalidation pings/sec | bursty | unbounded (29k/s seen) | ~2/sec | ~1/sec | up to 32 every 10s (bursty) |
| discv5 stale threshold | 30s | 30s | 12h | 12h | n/a |
| Re-ping while ping in flight | every cycle | every cycle | only on 30s timeout | livenessChecks/3 | one outstanding ping per peer |
A clean-DB ethrex node now reaches 22 peers in 3 minutes and 100+ within 15, with the discv4 packet rate sitting flat at the new baseline. The "Cached nodes" curve shows recovery from a restart with a warm peer cache (full table within ~10 minutes); the "Started from scratch" curve is the same node restarted with an empty database, where peer discovery does the full Kademlia walk and still gets there in roughly the same time:

2. GetPooledTransactions: stop asking a hundred peers for the same hash
How transactions move on the network
Once two execution clients connect over RLPx (the encrypted, framed P2P transport on top of TCP), they speak the eth wire protocol. The protocol defines how transactions propagate between mempools. The flow has three messages, and it has been this shape since eth/65 (EIP-2464, January 2020):
NewPooledTransactionHashes(0x08): "I have these transactions, here are their hashes (and, since eth/68, types and sizes)." A peer sends this for transactions it has newly learned about. The spec puts a soft cap of 4096 items (~150 KiB) per message.GetPooledTransactions(0x09):[request-id, [hash₁, hash₂, ...]]. "Give me the bodies of these hashes." Soft cap of 256 hashes (~8 KiB) per request.PooledTransactions(0x0a): the response, in the same order as the request, with permission to skip transactions the responder doesn't have.
The spec explains the announcement-then-fetch design: "as activity and transaction sizes increased on the Ethereum mainnet, the network bandwidth used for transaction exchange became a significant burden on node operators. The update reduced the required bandwidth by adopting a two-tier transaction broadcast system similar to block propagation." Before eth/65, every peer pushed full transaction bodies to every other peer for every transaction. With 50 peers and average transaction size of a few hundred bytes, you received the same transaction 50 times. Splitting announcement from fetch lets the receiver dedup against its own pool before pulling any body bytes.
The catch is that announcements still come from everyone. Gossip works by redundancy: a transaction broadcast onto the network reaches every well-connected node within a second or so, because every node forwards the hash to all of its peers. With a hundred peers, you hear about a popular transaction from all 100 of them in close succession. The protocol expects this; that's the whole point of the design. The receiver dedups before issuing GetPooledTransactions.
How clients handle this varies. Reth's TransactionFetcher (crates/net/network/src/transactions/fetcher.rs) keeps two structures: a global "in-flight or queued" set across all hashes, and per-hash TxFetchMetadata carrying an LRU of fallback peers, so a retry hits a different peer when the first request fails. Nethermind delegates dedup to the tx pool itself; Eth65ProtocolHandler filters announces with _txPool.IsKnown(hash) and NotifyAboutTx, and the pool uses a _retryCache that records a second peer's announcement as a fallback rather than a new request.
ethrex's earlier path didn't have an equivalent layer, and that's what we set out to add.
Where the previous design produced extra outbound requests
Each NewPooledTransactionHashes arrival, regardless of whether we'd already seen the hash from another peer thirty milliseconds earlier, triggered a full GetPooledTransactions request. The shape of the problem is structural: with H popular transactions flowing through gossip per second and P peers, the receiver gets on the order of H × P announcements but needs to send only H outbound requests (one per unique hash). The earlier path sent one outbound request per announcement, and during announcement spikes (a popular DEX trade or NFT mint can fire hundreds of transactions through gossip in a few hundred milliseconds), the multiplier across peers showed up on the outbound RLPx panel as thousands of requests per second on a backdrop of an order-of-magnitude lower announcement rate.
The fix, in two PRs
#6437 added the structural piece: an in-flight tracker. The structure lives on the per-connection RLPx state in crates/networking/p2p/rlpx/connection/server.rs as requested_pooled_txs: HashMap<u64, (NewPooledTransactionHashes, Vec<H256>, Instant)>, keyed by request ID and storing the hashes we asked for plus the request timestamp. A 30-second timeout (INFLIGHT_TX_TIMEOUT) sweeps stale entries. Incoming announcements consult the in-flight set and we drop any hash already pending. Cleanup happens on response receipt, on connection teardown, and on the timeout sweep.
#6443 followed up with the temporal half. Sending one GetPooledTransactions per surviving announcement isn't ideal even after dedup, since the message is a list, so we should bundle. The PR adds pending_tx_requests: Vec<(NewPooledTransactionHashes, Vec<H256>)> on the per-connection state, and a 50ms tick (TX_REQUEST_BATCH_INTERVAL) that drains it: hashes get merged via NewPooledTransactionHashes::merge(), chunked by 256 hashes (the spec's soft limit), and sent as a single request per chunk.
After we deployed both PRs, the outbound rate decoupled from the announcement rate:
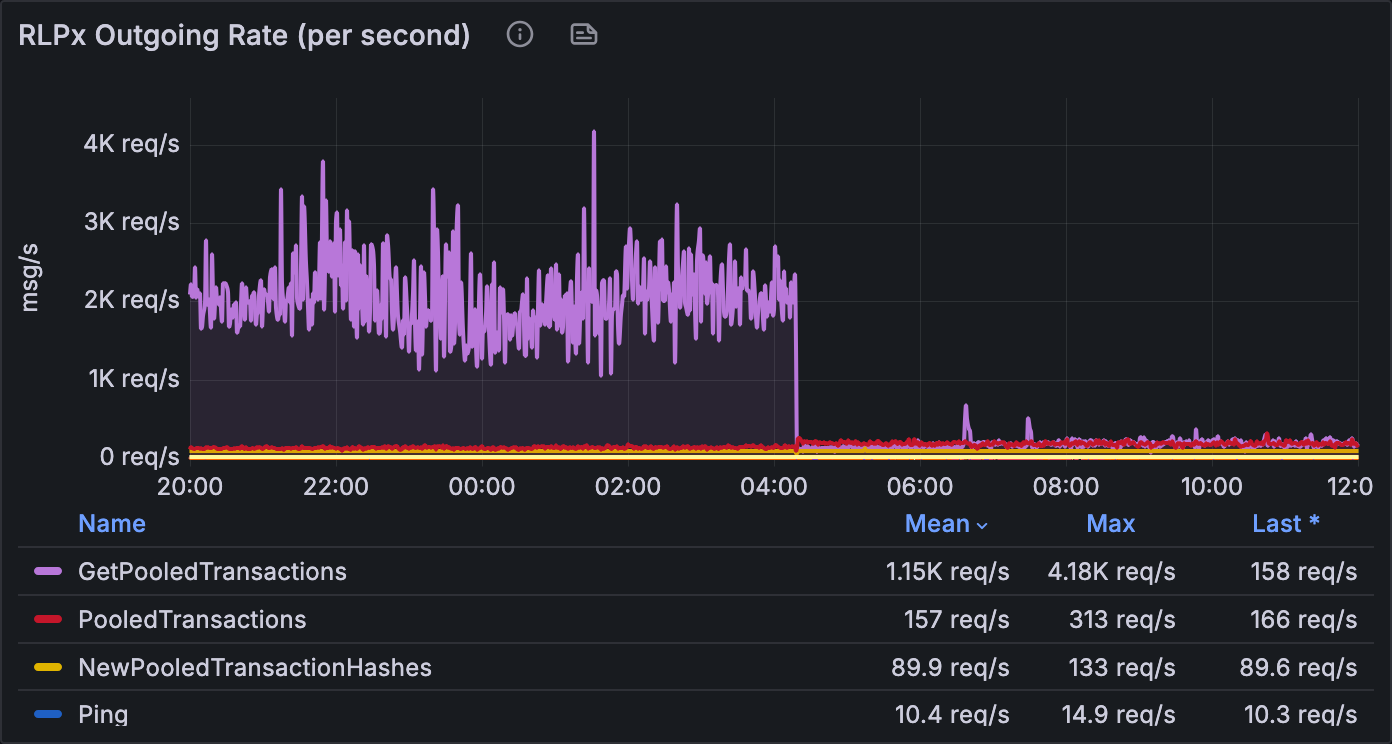
RLPx outgoing rate, per second. Before the deploy:
GetPooledTransactionsoutgoing held at 2K–4K req/s sustained (mean 4.18K req/s) for hours, while incomingNewPooledTransactionHashesran at only ~90 req/s. Every announcement got echoed and re-echoed as separate outbound requests. After the deploy at ~04:30:GetPooledTransactionscollapses to 158 req/s last, whileNewPooledTransactionHashesstays unchanged at ~90 req/s. Our outbound request rate now scales with unique transactions, not with how many peers tell us about each one.
The same eagerness/queueing tradeoff from §1 shows up here. Eager: send requests on arrival, get transactions into the mempool faster, waste bandwidth on duplicates. Queue: buffer for a window, dedup, send fewer requests, at the cost of a small added latency before a transaction makes it into the pool. 50ms is short enough that the mempool inclusion delay sits well below typical block intervals (multi-second on mainnet) and well below most peers' inbound de-dup window, and long enough that a popular transaction announced by a hundred peers in a 50ms window collapses to one request. With a flooding upstream, you absorb and dedup rather than mirror.
Reth doesn't do temporal batching at all; it relies on per-peer pack_request_eth68 to fill the 256-hash budget with whatever's queued at the moment of send, plus capacity-based concurrency limits (130 concurrent requests cluster-wide, 1 per peer). That works because reth never sends a per-announcement request in the first place; the queue is structural, not temporal. ethrex's 50ms window is the smallest interval that gets us most of the same compaction benefit without a more invasive refactor.
3. Full sync: tolerate your peers, and slow down when you're rushed
What is full sync anyway?
The most classical way an execution client builds the chain from genesis to the head is full sync. The client downloads headers and bodies and re-executes every transaction, building the state from scratch. Full sync runs much slower than snap sync (days to weeks on mainnet), but the same primitives drive catch-up mode. Shut down your node, wait a couple of hours or days, turn it back on, and it executes all the in-between blocks from your last known state up to the current head.
Full sync has two main components: a header download phase (decide which chain you're on, fetch headers up to the sync target), then a body-download-and-process phase. Header download is where peer selection lives, because it's the phase most sensitive to peer quality. Bodies parallelize; headers chain.
How peer scoring is supposed to work
A node with many peers picks one for every request: who do we ask? A request that fails (timeout, bad data, peer disconnects) costs a round-trip and a retry; a request that succeeds doesn't. The standard pattern is to keep a per-peer score that goes up on success and down on failure, and bias selection toward peers with higher scores. The exact model varies between clients:
- reth uses an additive reputation. Every peer starts at 0, penalties are large negative integers (
Timeout = -4096,BadMessage = -16384,BadProtocol = i32::MIN), and a periodictick()decays scores back toward 0 as a way of "rewarding" still-connected peers. Trusted peers cap their losses. CrossingBANNED_REPUTATION = -51200triggers a disconnect-and-ban (crates/net/network-types/src/peers/reputation.rs). - nethermind doesn't score peers for sync; its
BySpeedStrategyranks peers by an EMA of measured transfer speed overTransferSpeedType.Headers, and switches off the current peer when a speed-ratio and a min-speed-change threshold both trip (Nethermind.Synchronization/Peers/AllocationStrategies/BySpeedStrategy.cs). It's a speed meter, not a reputation credit system. - ethrex uses a much narrower band:
MAX_SCORE = 50, MIN_SCORE = -50with aMIN_SCORE_CRITICAL = -150for malicious behaviour (peer_table.rs:38-41). Scores are unit-incremented, and selection weight (peer_table.rs:1315) is a normalized function of the score range.
The hard part: how do you tell whether a peer is unresponsive or slow?
Header downloads: making the score inform selection (#6428)
Three changes in the header download loop:
-
Selection is now score-weighted instead of uniform random. The score mechanism existed; the selector wasn't reading it. Selection now weights by score, with enough randomness preserved that new peers still get tried and we don't lock onto a single peer.
-
Score goes up on success too. Previously we only decremented the score on timeouts and didn't increment it on a successful message, so ethrex grew overly pessimistic about peer quality.
On the other hand, empty responses are not penalized. A peer responding with an empty body to a header request near the chain tip is telling us "I don't have anything past block X", which is correct behaviour at the edge of its known chain, not a failure. Non-empty unchained responses (where
headers[i].parent_hash != headers[i-1].hash()) get penalized; those are invalid. -
Consecutive failures, not cumulative. The
consecutive_failurescounter was meant to mean "this peer has failed N times in a row, drop it." Previously, the counter didn't reset on a successful response, so a long-lived peer that served headers for hours could accumulate enough total failures to get dropped despite a fine overall success rate. After the fix (crates/networking/p2p/sync/full.rs:149), the counter resets to zero on every successful header batch. The same fix landed in the equivalent code path in snap sync.
The per-request timeout also dropped from 15 seconds to 5 seconds (PEER_REPLY_TIMEOUT in snap/constants.rs). With 42 peers in the rotation, the older 15-second timeout meant a single "ask everyone, see who answers" round took 10+ minutes when slow peers came up first. Five seconds gives a healthy peer enough headroom to respond, and it disqualifies a slow peer an order of magnitude faster.
The composite effect: the selection loop concentrates traffic on peers that have been useful, and a flaky peer no longer blocks progress for everyone behind it. On a chain with variable peer quality like hoodi, header downloads keep moving even when individual peers go slow or unresponsive.
Block-by-block fallback (#6464)
Header downloads are one piece. The other piece, #6464, handles execution. We saw a hoodi full sync that failed at block 443,055 with a StateRootMismatch during batch execution, regardless of which peers we used.
ethrex's full-sync execution path runs blocks in batches, not one by one. The batch path keeps a single shared in-memory view of state across the blocks in the batch, computes per-block state diffs, applies them in order, and at the end of the batch reconciles the merkleized root against the network's expected root. Batching is a real performance win: it amortizes the cost of trie work across many blocks and lets us defer the expensive merkle-Patricia recomputation until we have a coherent set of state changes to apply at once.
Batching has a sharper failure mode than block-by-block, though. If the per-block state view observes dirty data from a sibling block in the batch (for instance, a write that should be logically committed only at the end of one block leaking into the read set of the next), the resulting state root is wrong and the entire batch fails. That's what happened at hoodi 443,055.
We could chase the specific issue, but batching is optimistic and predicting all possible inter-block interactions might not be feasible, so to get the best of both worlds, we changed the policy: when add_blocks_in_batch fails with a post-execution error, we re-run the same range one block at a time through the pipeline path (run_blocks_pipeline, crates/networking/p2p/sync/full.rs:550-573), which uses a fresh VM state per block and avoids the cross-block cache contamination problem.
The classification (is_post_execution_error, full.rs:538-548) is precise about what triggers the retry: GasUsedMismatch, StateRootMismatch, ReceiptsRootMismatch, RequestsHashMismatch, BlockAccessListHashMismatch, BlobGasUsedMismatch. Each of these is something the EVM concludes only after running the whole block; none can be checked from header/body inspection alone.
The retry is safe because add_blocks_in_batch is all-or-nothing: it doesn't write the batch's state changes to durable storage until every block in the batch has succeeded. The implementation in crates/blockchain/blockchain.rs:2180-2295 accumulates execution results in memory and calls store_block_updates only at the end. A failed batch leaves the database byte-identical to its pre-batch state, so the pipeline retry starts from a clean base.
The error filter is narrow on purpose. Pre-execution validation errors (bad header, malformed body, gas mismatch caught before the EVM is even entered) don't trigger the fallback. Switching execution mode wouldn't help (the block is invalid), and retrying it would burn double the CPU before rejecting it anyway. There's also a mild DoS angle: if the fallback fired on every InvalidBlock variant, a peer feeding us a malformed block could force us to execute it twice. The narrow filter keeps the fallback bounded to the class of errors that are plausibly batch-mode false positives.
With the fallback in place and more stable header downloads, hoodi now full-syncs from genesis to head unattended, and nodes catching up after downtime come back online without operator hand-holding.
What this adds up to
The combined effect of these merges, observed across our mainnet nodes:
- Discovery traffic is steady and bounded. Packet rates sit in the low tens of req/s, so operators on bandwidth-sensitive providers can run nodes without hitting abuse thresholds.
- Mempool bandwidth scales with unique transactions, not with peer count. Outbound
GetPooledTransactionsrate decouples from incoming announcement rate. The in-flight tracker absorbs duplicates, and the 50ms batching window collapses spikes from many announcing peers into a single request. - Header downloads progress across a mixed peer pool. The selection loop concentrates on peers that have been useful, slow peers no longer block the rotation, and long-lived useful peers don't get dropped over accumulated failures from a long session.
- Full sync recovers from edge cases on its own. A batch-execution false positive falls through to the per-block pipeline path, so a single bad batch no longer requires operator intervention.
A few of these fixes (discovery rate-limiting, the in-flight tracker, the batch-execution fallback) illustrate a pattern that recurs across networking code: an eager implementation works fine in development and even on long-running nodes, but produces noisy traffic under load, because the network has feedback loops and amplification factors that don't show up until you measure them. The reservoir-sample-and-rate-limit shape of the discovery fix and the buffer-and-batch shape of the pooled-tx fix share a structure because the underlying constraint is the same: when the upstream fans out, the right local response is to absorb and dedup rather than mirror.
Plenty more sits on the roadmap on the same surfaces: peer scoring with persistence across restarts, finer-grained discovery table maintenance, and cache-pollution work on the batch-execution path. The operational floor sits where it should, with stable peer counts, flat packet rates, and sync runs that complete unattended.
