Weld: accelerating numpy, scikit and pandas as much as 100x with Rust and LLVM
After working for weeks with Python’s data science stack and R I started to ask my self if there could not be a common intermediate…

Interview with Weld’s main contributor: accelerating numpy, scikit and pandas as much as 100x with Rust and LLVM
After working for weeks with Python’s and R’s data science stack I started to ask my self if there could be a common intermediate representation, similar to CUDA, that could be used by many languages. There should be something better than reimplementing and optimizing the same methods in each language. In addition to that, having a common runtime that could optimize the whole program instead of each function separately would be better. After a few days of researching and testing different projects I found Weld (you can also read its paper). To my surprise, one of the creators of Weld is Matei Zaharia, who also is the creator of Spark.
That is how I contacted and interviewed Shoumik Palkar, the main contributor of Weld. Shoumik is a Ph.D. student in the Computer Science department at Stanford University, that is advised by Matei Zaharia.
Weld is far from being production ready but it is promising. If you are interested in the future of data science and in Rust, you will like this interview.

What was the motivation to develop weld and what problem’s does it solve?
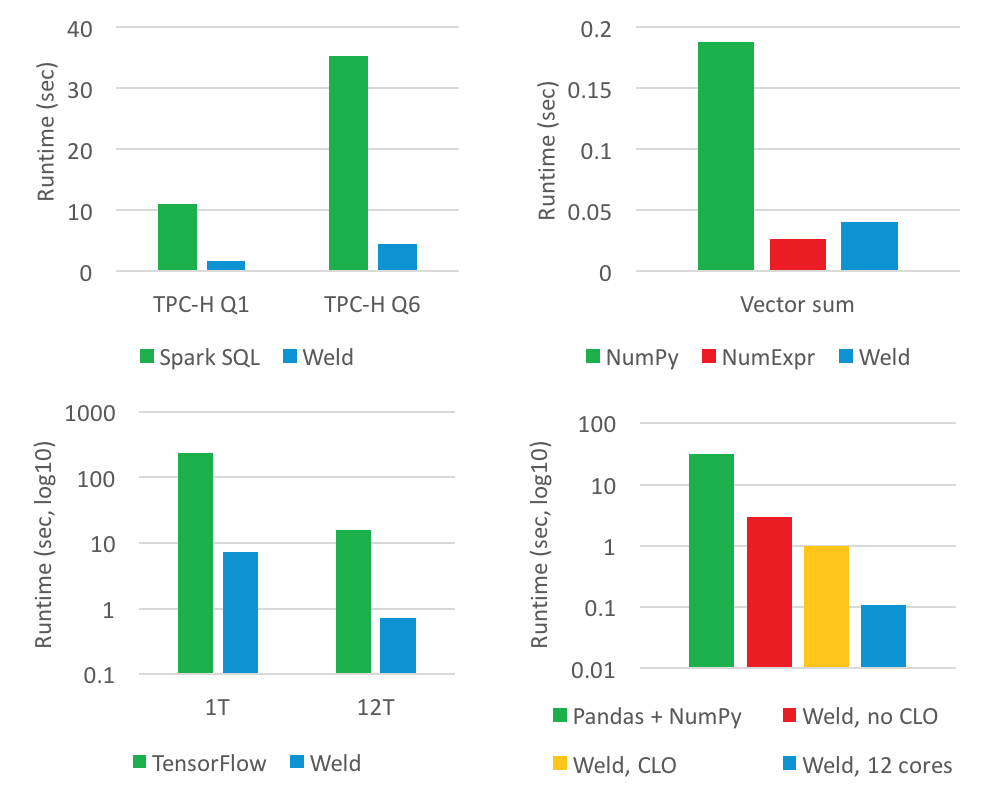
The motivation behind Weld is to provide bare-metal performance for applications that rely on existing high-level APIs such as NumPy and Pandas. The main problem it solves is enabling cross-function and cross-library optimizations that other libraries today don’t provide. In particular, many commonly used libraries provide state-of-the-art implementations for algorithms on a per-function basis (e.g., a fast join algorithm implemented in C in Pandas, or a fast matrix multiply in NumPy), but do not provide any facility for enabling optimization across these functions (e.g., preventing unnecessary scans of memory when performing a matrix multiply followed by an aggregation). Weld provides a common runtime that enables libraries to express computations in a common IR; that IR can then be optimized using a compiler optimizer, and can then be JIT’d to parallel native machine code with optimizations such as loop fusion, vectorization, etc. Weld’s IR is natively parallel, so programs expressed in it can always be trivially parallelized.
We also have a new project called split annotations which will integrate with Weld that’s meant to lower the barrier for enabling these optimizations in existing libraries.
Optimizing numpy, pandas and scikit wouldn’t be easier? How faster it is?
Weld provides optimizations across functions in these libraries, whereas optimizing these libraries would only make individual function calls faster. In fact, many of these data libraries are already highly optimized on a per-function basis, but deliver performance below the limits of modern hardware because they do not exploit parallelism or do not make efficient use of the memory hierarchy. For example, many NumPy ndarray functions are already implemented in C, but calling each function requires scanning over each input in entirety. If these arrays do not fit in the CPU caches, most of the execution time can go into loading data from main memory rather than performing computations. Weld can look across individual function calls and perform optimizations such as loop fusion that will keep data in the CPU caches or registers. These kinds of optimizations can improve performance by over an order of magnitude on multi-core systems, because they enable better scaling.
What is Baloo?
Baloo is a library that implements a subset of the Pandas API using Weld. It was developed by Radu Jica, who was a Master’s student in CWI in Amsterdam. The goal of Baloo is to provide the kinds of optimizations described above in Pandas to improve its single-threaded performance, reduce memory usage, and to enable parallelism.
Does Weld/Baloo support out-of-core operations (say, like Dask) to handle data that does not fit in memory?
Weld and Baloo currently do not support out-of-core operations, though we’d love open source contributions on this kind of work!
Why did you choose Rust and LLVM to implement weld? Was Rust your first choice?
We chose Rust because:
- It has a very minimal runtime (essentially just bounds checks on arrays) and is easy to embed into other languages such as Java and Python
- It contains functional programming paradigms such as pattern matching that make writing code such as pattern matching compiler optimizations easier
- It has a great community and high quality packages (called “crates” in Rust) that made developing our system easier.
We chose LLVM because its an open source compiler framework that has wide use and support; we generate LLVM directly instead of C/C++ so we don’t need to rely on the existence of a C compiler, and because it improves compilation times (we don’t need to parse C/C++ code).
Rust was not the first language in which Weld was implemented; the first implementation was in Scala, which was chosen because of its algebraic data types and powerful pattern matching. This made writing the optimizer, which is the core part of the compiler, very easy. Our original optimizer was based on the design of Catalyst, which is Spark SQL’s extensible optimizer. We moved away from Scala because it was too difficult to embed a JVM-based language into other runtimes and languages.
If Weld targets CPU and GPUS how does it compare to projects like RAPIDS that implements python data science libraries but for the GPU?
The main way Weld differs from systems such as RAPIDS is that it focuses on optimizing applications across individually written kernels by JIT compiling code rather than providing optimized implementations of individual functions. For example, Weld’s GPU backend would JIT-compile a single CUDA kernel optimized for the end-to-end application on the fly rather than calling existing individual kernels. In addition, Weld’s IR is meant to be hardware independent, allowing it to target GPUs as well as CPUs or custom hardware such as vector accelerators. Of course, Weld overlaps significantly and is influenced by many other projects in the same space, including RAPIDS. Runtimes such as Bohrium (a lazily evaluated NumPy) and Numba (a Python library that enables JIT compilation of numerical code) both share Weld’s high level goals, while optimizers systems such as Spark SQL have directly impacted Weld’s optimizer design.
Does weld have other applications outside data science library optimizations?
One of the most exciting aspects of Weld’s IR is that it supports data parallelism natively. This means that loops expressed in the Weld IR are always safe to parallelize. This makes Weld an attractive IR for targeting new kinds of hardware. For example, collaborators at NEC have demonstrated that they can use Weld to run Python workloads on a custom high-memory-bandwidth vector accelerator just by adding a new backend to the existing Weld IR. The IR can also be used to implement the physical execution layer in a database, and we plan to add features that will make it possible to compile a subset of Python to Weld code as well.
Are the libraries ready to be used on real-life projects? If not, when can we expect them to be ready?
Many of the examples and benchmarks we’ve tested these libraries on are taken from real workloads, so we’d love it if users tried out the current versions for their own applications, provided feedback, and (best of all) submitted open source patches. That said, we don’t expect everything to work out of the box on real-life applications just yet. Our next few releases over the following couple months are focusing exclusively on usability and robustness of the Python libraries; our goal is to make the libraries good enough for inclusion in real-life projects, and to seamlessly fall back to the non-Weld versions of the libraries in places where support is yet to be added.
As I mentioned on the first answer, one path toward making this easier comes in the form of a related project called split annotations (code and academic paper). Split annotations are a system that allow annotating existing code to define how to split, pipeline, and parallelize it. They provide the optimization that we found was most impactful in Weld (keeping chunks of data in the CPU caches between function calls rather than scanning over the entire dataset), but they are significantly easier to integrate than Weld because they reuse existing library code rather than relying on a compiler IR. This also makes them easier to maintain and debug, which in turn improves their robustness. Libraries without full Weld support can fall back to split annotations when Weld is not supported, which will allow us to incrementally add Weld support based on feedback from users while still enabling some new optimizations.
